
大数据-96 Spark 集群 SparkSQL Scala编写SQL操作SparkSQL的数据源:JSON、CSV、JDBC、Hive
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

SparkSQL 读写_Hive_整合 | 学习笔记
开发者学堂课程【大数据 Spark 2020版(知识精讲与实战演练)第三阶段:SparkSQL 读写_Hive_整合】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/690/detail/12058SparkSQL 读写_Hive_整合 内容介绍:一、思路梳理二、整合步骤三、课堂总结&...
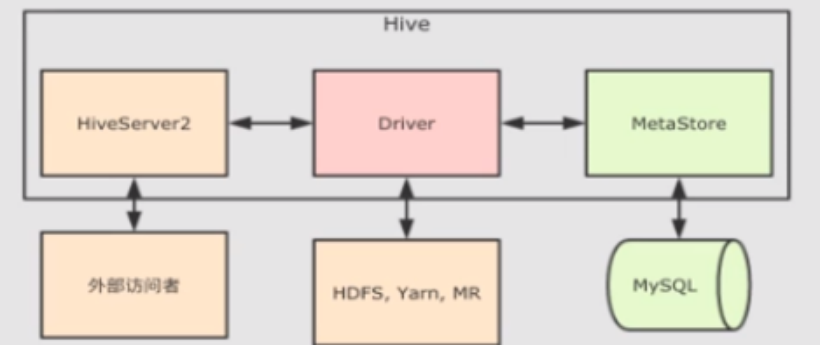
SparkSQL 读写_Hive_写入数据_配置 | 学习笔记
开发者学堂课程【大数据 Spark 2020版(知识精讲与实战演练)第三阶段:SparkSQL 读写_Hive_写入数据_配置】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/690/detail/12062SparkSQL 读写_Hive_写入数据_配置 内容介绍:一、步骤二、实操&...
SparkSQL 读写_Hive_写入数据_编码和配置 | 学习笔记
开发者学堂课程【大数据 Spark 2020版(知识精讲与实战演练)第三阶段:SparkSQL 读写_Hive_写入数据_编码和配置】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/690/detail/12063SparkSQL 读写_Hive_写入数据_编码和配置 内容介绍:一、步骤一....
SparkSQL 读写_Hive_读取 Hive 表 | 学习笔记
开发者学堂课程【大数据 Spark 2020版(知识精讲与实战演练)第三阶段:SparkSQL 读写_Hive_读取 Hive 表】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/690/detail/12060SparkSQL 读写_Hive_读取 Hive 表 内容介绍:一、相关命令二....

SparkSQL 读写_Hive_创建 Hive 表 | 学习笔记
开发者学堂课程【大数据 Spark 2020版(知识精讲与实战演练)第三阶段:SparkSQL 读写_Hive_创建 Hive 表】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/690/detail/12059SparkSQL 读写_Hive_创建 Hive 表 内容介绍:一、步骤二、实....

SparkSQL 读写_Hive_SparkSQL 创建 Hive 表 | 学习笔记
开发者学堂课程【大数据 Spark 2020版(知识精讲与实战演练)第三阶段:SparkSQL 读写_Hive_SparkSQL 创建 Hive 表】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/690/detail/12061SparkSQL 读写_Hive_SparkSQL 创建 Hive 表....
API接口创建sparksql作业和hive sql作业 执行的sql是怎么传进去的?
E-MapReduce 的API接口创建sparksql作业和hive sql作业 执行的sql是怎么传进去的 我看网上文档也没说明
SparkSQL与Hive metastore Parquet转换
本文转载自公众号:大数据学习与分享 Spark SQL为了更好的性能,在读写Hive metastore parquet格式的表时,会默认使用自己的Parquet SerDe,而不是采用Hive的SerDe进行序列化和反序列化。该行为可以通过配置参数spark.sql.hive.convertMetastoreParquet进行控制,默认true。 这里从表schema的处理角度而言,就必须注.....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。