
MapReduce中的Map和Reduce函数分别是什么作用?
MapReduce中的Map和Reduce函数分别是什么作用?在MapReduce中,Map函数和Reduce函数是两个核心操作,用于处理大规模数据集。Map函数的作用是将输入数据集划分为若干个小数据块,并将每个数据块映射为(key, value)对。Map函数接受一个输入数据块,对其进行处理,并生成一个或多个(key, value)对作为输出。Map函数的输出将作为Reduce函数的输入。Re....
32 MAPREDUCE的map端join算法实现
原理阐述适用于关联表中有小表的情形;可以将小表分发到所有的map节点,这样,map节点就可以在本地对自己所读到的大表数据进行join并输出最终结果,可以大大提高join操作的并发度,加快处理速度。实现示例1.在mapper类中预先定义好小表,进行join2.引入实际场景中的解决方案:一次加载数据库或者用distributedcache。public class TestDistributedCa....
Hadoop框架下MapReduce中的map个数如何控制
一个job的map阶段并行度由客户端在提交job时决定客户端对map阶段并行度的规划基本逻辑为:一、将待处理的文件进行逻辑切片(根据处理数据文件的大小,划分多个split),然后每一个split分配一个maptask并行处理实例二、具体切片规划是由FileInputFormat实现类的getSplits()方法完成切分规则如下:1.简单地按照文件的内容长度进行切片2.切片大小默认是datanod....
MapReduce执行机制之Map和Reduce源码分析
1、Mapper 类 * Maps input key/value pairs to a set of intermediate key/value pairs. * * <p>Maps are the individual tasks which transform input records into a * intermediate records. The tr...
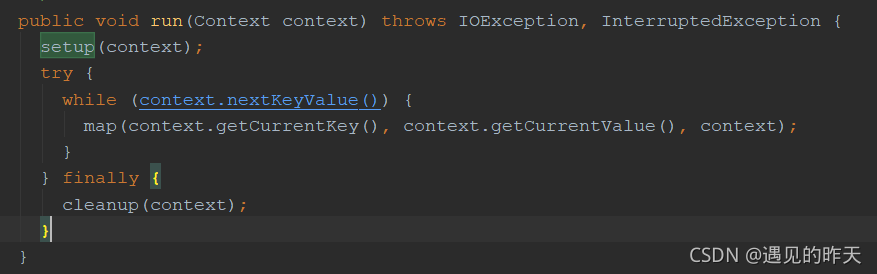
map函数中为什么忽略键?map函数输出什么时候由MapReduce框架处理呀?
map函数中为什么忽略键?map函数输出什么时候由MapReduce框架处理呀?
类中MapReduce的工作原理是什么?map阶段和reduce阶段共同点是什么?
类中MapReduce的工作原理是什么?map阶段和reduce阶段共同点是什么?
使用emr的mapreduce在map阶段怎么获取split文件的路径呢?
使用emr的mapreduce在map阶段怎么获取split文件的路径呢?我需要根据文件的名,来判断走不同的逻辑的。
记Hadoop2.5.0线上mapreduce任务执行map任务划分的一次问题解决
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/beliefer/article/details/51397729 前言 近日在线上发现有些mapreduce作业的执行时间很长,我们需要解决这个问题。输入文件的大小是5G,采用了lzo压缩,整个集群的默认b...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。