
使用Hadoop命令操作OSS/OSS-HDFS
在使用阿里云EMR Serverless Spark的Notebook时,您可以通过Hadoop命令直接访问OSS或OSS-HDFS数据源。本文将详细介绍如何通过Hadoop命令操作OSS/OSS-HDFS。
如何通过ES-Hadoop实现Spark读写阿里云Elasticsearch数据
Spark是一种通用的大数据计算框架,拥有Hadoop MapReduce所具有的计算优点,能够通过内存缓存数据为大型数据集提供快速的迭代功能。与MapReduce相比,减少了中间数据读取磁盘的过程,进而提高了处理能力。本文介绍如何通过ES-Hadoop实现Hadoop的Spark服务读写阿里云Elasticsearch数据。
[AIGC ~大数据] 深入理解Hadoop、HDFS、Hive和Spark:Java大师的大数据研究之旅
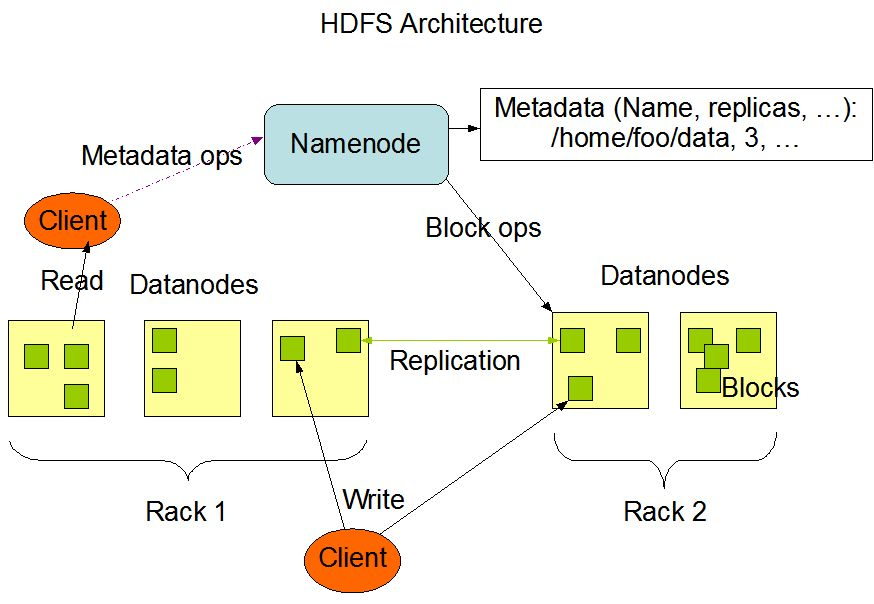
作为一位Java大师,我始终追求着技术的边界,最近我将目光聚焦在大数据领域。在这个充满机遇和挑战的领域中,我深入研究了Hadoop、HDFS、Hive和Spark等关键技术。本篇博客将从"是什么"、"为什么"和"怎么办"三个角度,系统地介绍这些技术。是什么?HadoopHadoop是一个开源的分布式计算框架,它能够高效地处理大规模数据集。它的核心是分布式文件系统HDFS和分布式计算模型MapRe....
干翻Hadoop系列文章【02】:Hadoop、Hive、Spark的区别和联系
第一章:Hadoop和Hive以及Spark的关系是什么?Hadoop和Hive、Spark都是大数据领域的技术栈。一:大数据领域当中以后两个最为核心的问题1:数据怎么存储2:海量数据怎么计算单机系统时代。所有数据都在一个计算机上进行存储,数据处理任务都是IO密集型,而不是CPU密集型。数据分布式存储大数据时代 ,海量数据导致我们一台数据服务存不下。这样的话,我们需要一一直加机器进行分布式存储。....
如何在EMR的Hadoop集群中运行Spark作业对接DataHub数据_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文介绍如何在E-MapReduce的Hadoop集群,运行Spark作业消费DataHub数据、统计数据个数并打印出来。
Hadoop、Hive、Spark 之间的关系?
5G 时代,运营商网络不断提速,成本越来越低,流量越来越便宜。给 互联网、物联网、互联网+ 各个行业的高速发展创造了非常好的有利条件,同时也产生了海量数据。如何做好数据分析,计算,提取有价值信息,大数据技术一直是一个热门赛道。今天我们就对 Hadoop、Hive、Spark 做下分析对比。HadoopHadoop 称为大数据技术的基石。由两部分组成,分布式存储(HDFS)和分布式计算(MapRe....
java,mysql,hadoop,cdh,hive,spark,ntp,zookeeper,kafka,storm,redis,flume,git 安装详解
顶部 ---------------------------------------------------------------------------------------------------------------------------------- 0.关闭防火墙 1.修改hosts 2.检查每台机器的 hostname 3.安装jdk 4.网络、ho...
Hadoop(HDFS、YARN、HBase、Hive和Spark等)默认端口表
端口 作用 9000 fs.defaultFS,如:hdfs://172.25.40.171:9000 9001 dfs.namenode.rpc-address,DataNode会连接这个端口 50070 dfs.na...
【Hadoop Summit Tokyo 2016】Hivemall: Apache Hive/Spark/Pig 的可扩展机器学习库
本讲义出自 Makoto YUI与NTT Takashi Yamamuro在Hadoop Summit Tokyo 2016上的演讲,主要介绍了Hivemall的相关知识以及Hivemall在Spark上的应用,Hivemall是可以用于Apache Hive/Spark/Pig 的可扩展机器学习库。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop spark相关内容
- hadoop spark大数据处理
- 数据湖hadoop spark
- 技术hadoop spark
- spark模式hadoop
- 大数据spark hadoop
- spark部署hadoop
- spark hadoop mapreduce
- spark hadoop wordcount单词计数实例
- 大数据技术hadoop spark
- maxcompute spark hadoop
- hadoop spark flink
- 分布式hadoop spark
- hadoop spark数据处理
- spark hadoop分布式
- hadoop spark数据
- hadoop spark hive
- hadoop spark组件
- hadoop spark概念
- hadoop spark安装
- hadoop spark实战源码
- hadoop spark原理
- hadoop spark hbase
- 云计算hadoop spark
- spark hadoop pdf
- hadoop spark异同
- spark编译hadoop
- spark hadoop scala
- hadoop spark hive数据
- storm spark hadoop
- spark hadoop框架
hadoop更多spark相关
- hadoop zookeeper spark
- hadoop spark步骤
- hadoop spark分布式
- hadoop spark standalone
- hadoop实战spark
- hadoop spark案例
- hadoop概念学习spark
- hadoop summit tokyo apache spark
- spark summit hadoop
- spark hadoop参数
- spark与hadoop大数据分析hadoop spark
- hadoop学习spark
- hadoop storm spark
- hadoop ha spark
- hadoop spark mesos
- hadoop大数据平台spark
- hadoop summit tokyo spark扩展
- hadoop yarn spark
- spark学习hadoop
- spark hadoop解决方案
hadoop您可能感兴趣
- hadoop开发环境
- hadoop hbase
- hadoop集群
- hadoop数据处理
- hadoop数据分析
- hadoop入门
- hadoop系统
- hadoop技术
- hadoop大数据
- hadoop集群管理
- hadoop hdfs
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop分布式
- hadoop数据
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作