
模型小,还高效!港大最新推荐系统EasyRec:零样本文本推荐能力超越OpenAI、Bert
香港大学的研究者们最近提出了一种名为EasyRec的新型推荐系统,旨在解决现有推荐算法在零样本学习场景中的局限性。EasyRec的提出,源于对语言模型(LMs)在理解和生成文本方面强大能力的观察。 在传统的推荐系统中,算法通常依赖于用户和物品的唯一ID来学习交互数据的表示。然而,这种依赖性限制了它们在实际的零样本...
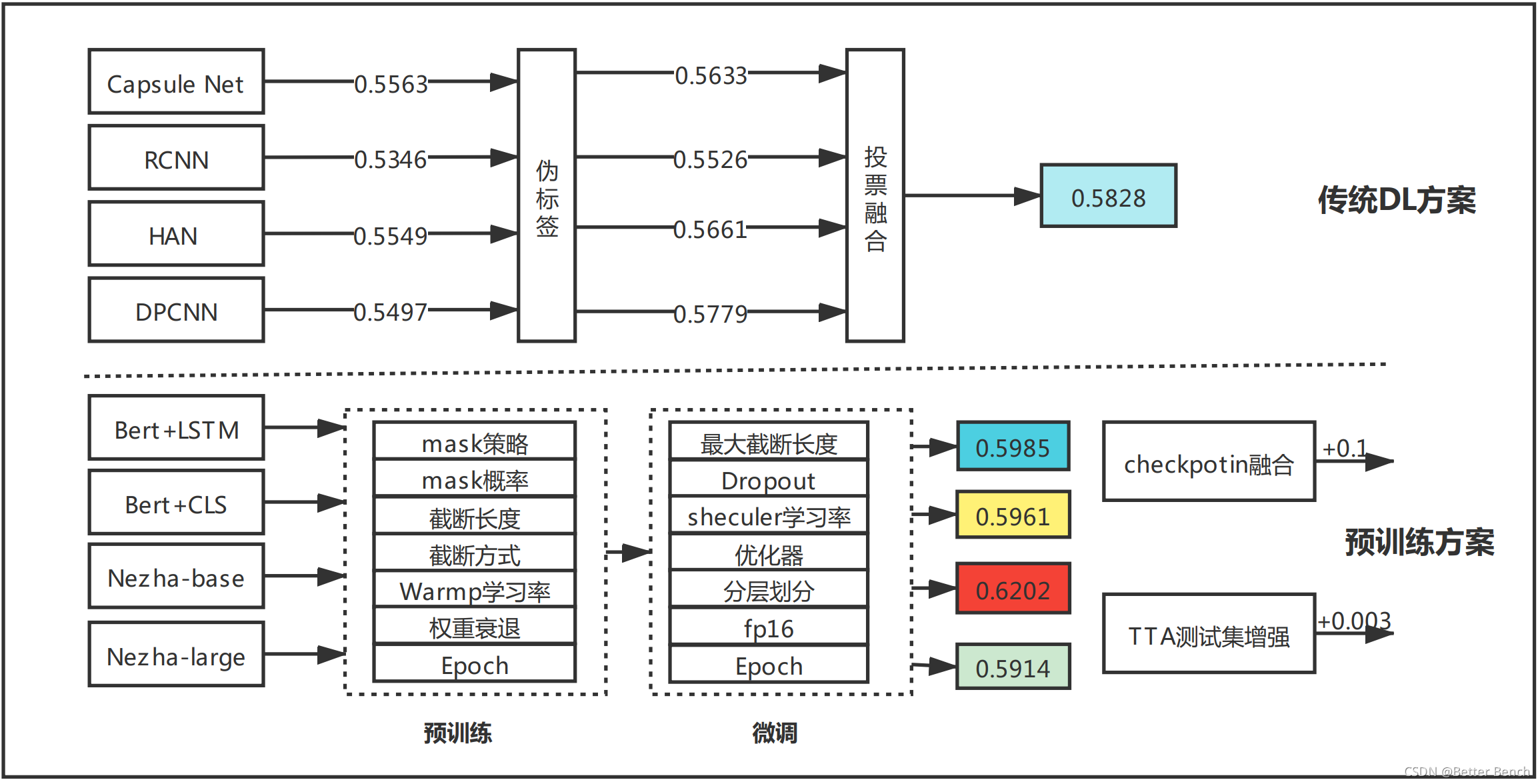
2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】3 Bert和Nezha方案
相关链接 【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】1 初赛Rank12的总结与分析【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】2 DPCNN、HAN、RCNN等传统深度学习方案【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】3 Bert和Nezha方案 1 引言 2 NEZHA方案 (1)...
算法金 | 秒懂 AI - 深度学习五大模型:RNN、CNN、Transformer、BERT、GPT 简介
1. RNN(Recurrent Neural Network) 时间轴 1986年,RNN 模型首次由 David Rumelhart 等人提出,旨在处理序列数据。 关键技术 循环结构序列处理长短时记忆网络(LSTM)和门控循环单元(GRU) 核心原理 RNN 通过循环结构让网络记住...

使用Python实现深度学习模型:BERT模型教程
BERT(Bidirectional Encoder Representations from Transformers)是Google提出的一种用于自然语言处理(NLP)的预训练模型。BERT通过双向训练Transformer,能够捕捉到文本中词语的上下文信息,是NLP领域的一个里程碑。 在本文中,...

训练你自己的自然语言处理深度学习模型,Bert预训练模型下游任务训练:情感二分类
基础介绍:Bert模型是一个通用backbone,可以简单理解为一个句子的特征提取工具更直观来看:我们的自然语言是用各种文字表示的,经过编码器,以及特征提取就可以变为计算机能理解的语言了下游任务:提取特征后,我们便可以自定义其他自然语言处理任务了,以下是一个简单的示例(效果可能不好,但算是一个基本流程)数据格式:模型训练:我们来训练处理句子情感分类的模型,代码如下import torch fro....
如何使用Blade优化通过TensorFlow训练的BERT模型
BERT(Bidirectional Encoder Representation from Transformers)是一个预训练的语言表征模型。作为NLP领域近年来重要的突破,BERT模型在多个自然语言处理的任务中取得了最优结果。然而BERT模型存在巨大的参数规模和计算量,因此实际生产中对该模型具有强烈的优化需求。本文主要介绍如何使用Blade优化通过TensorFlow训练的BERT模型。
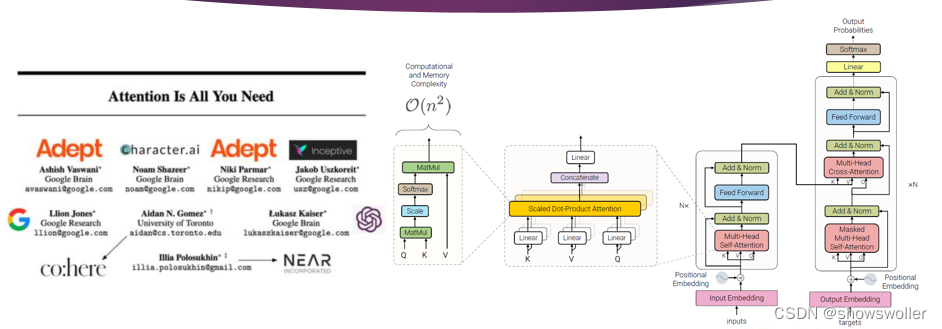
预训练语言模型中Transfomer模型、自监督学习、BERT模型概述(图文解释)
一、Transformer变换器模型Transformer模型的编码器是由6个完全相同的层堆叠而成,每一层有两个子层 。第一个子层是多头自注意力机制层,第二个子层是由一一个简单的、按逐个位置进行全连接的前馈神经网络。在两个子层之间通过残差网络结构进行连接,后接一一个层正则化层。可以得出,每一一个子层的输出通过公式可以表示为LayerNorm(x + Sublayer(x)),其中,Sublaye....
lda模型和bert模型的文本主题情感分类实战
视频参考:lda模型和bert模型的文本主题情感分类实战_哔哩哔哩_bilibili数据展示:模型结构:主要代码:import torch from torch import nn from torch import optim import transformers as tfs import math import numpy as np import pandas as pd from s....

AI加速:使用TorchAcc实现Bert模型分布式训练加速_人工智能平台 PAI(PAI)
阿里云PAI为您提供了部分典型场景下的示例模型,便于您便捷地接入TorchAcc进行训练加速。本文为您介绍如何在BERT-Base分布式训练中接入TorchAcc并实现训练加速。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
bert模型相关内容
- bert模型架构
- 训练bert large模型
- bert模型训练
- 训练模型bert
- nlp bert模型
- bert模型方法
- 部署bert模型
- bert模型文件
- bert文本分类模型
- 模型bert预训练
- bert模型原理
- 预训练语言模型模型bert
- 预训练模型bert
- bert模型配置
- bert模型推理
- transformer模型bert
- 模型推理bert
- 模型推理onnx bert特征抽取
- 模型推理bert方案
- bert模型框架
- 模型xlnet bert
- 任务bert模型
- bert文本分类实战模型
- 文本分类bert模型
- bert谷歌模型
- 构建bert模型蒸馏textcnn
- 怎么使用构建bert模型蒸馏textcnn
- bert模型nlp