
Hive 任务调优实践总结
一、背景:最近由于要回刷数据调优前:map数:30000 单个map 运行7-8分钟reduce数:50 单个reduce 运行了20h 还没完成,还经常失败整体耗时20多个小时还没有完成并且失败了,明显数据倾斜reduce 某个节点跑很久出不来调优后: map数:30000 单个map 运行7-8分钟reduce数:1000 单个reduce 运行了1h左....

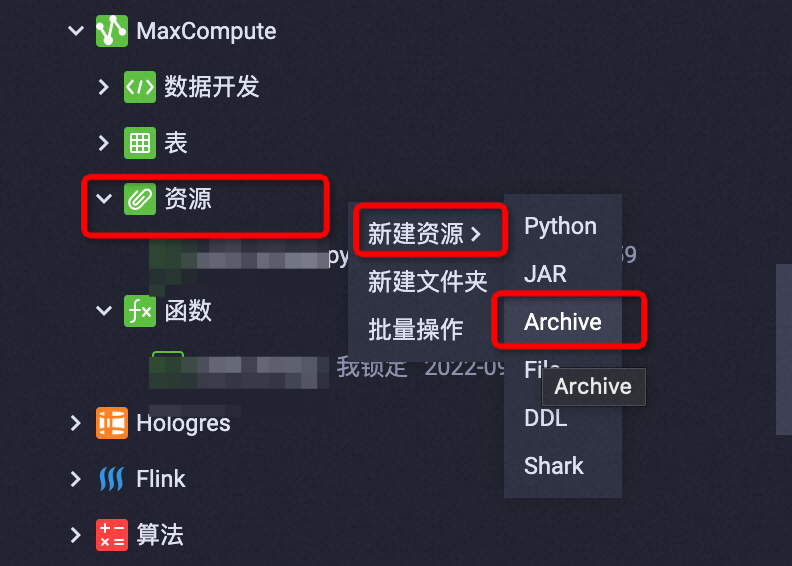
阿里云MaxCompute-Hive UDF(Java)迁移上云实践
1. 一小时快速迁移法-兼容Hive参考文档:https://help.aliyun.com/zh/maxcompute/user-guide/write-a-hive-udf-in-java#task-2105893特点:不需要改动代码,继承自Hive的udf基类,诸如UDF,GenericUDF1.1. 打包注意事项MaxCompute兼容的Hive版本为2.1.0,对应Hadoop版本为2....
Hive SQL 迁移 Flink SQL 在快手的实践
摘要:本文整理自快手数据架构工程师张芒,阿里云工程师刘大龙,在 Flink Forward Asia 2022 生产实践专场的分享。本篇内容主要分为四个部分: Flink 流批一体引擎 Flink Batch 生产实践 核心优化解读 未来规划 点击查看原文视频 & 演讲PPT 一、Flink 流批一体引擎 1.1 Lambda...

《离线和实时大数据开发实战》(五)Hive 优化实践2
五、大表 Join 大表优化如果上述 mapjoin 中小表 dim_seller 很大呢?比如超过了 1GB 的大小?这种就是大表join 大表的问题 。这类问题相对比较复杂,我们首先引入具体的问题场景,然后基于此介绍各种优化方案。5.1 问题场景我们先假设一个问题场景:A 表为一个汇总表,汇总的是卖家买家最近 N 天交易汇总信息,即对于每个卖家最近 N 天,其每个买家共成交了多少单、总金额是....

《离线和实时大数据开发实战》(五)Hive 优化实践1
文章目录前言一、离线数据的主要挑战:“数据倾斜”二、Hive 的优化三、Join 无关的优化3.1 group by 引起的倾斜优化3.2 count distinct 优化四、大表 Join 小表优化五、大表 Join 大表优化5.1 问题场景方案 1:转化为 mapjoin方案 2:join 时用 case when 语句方案 3:倍数B表,再取模join方案 4:动态一分为二前言前面,我们....

《离线和实时大数据开发实战》(四)Hive 原理实践2
Hive DDL1. 创建表CREATE TABLE:用于创建一个指定名字的表 。如果相同名字的表已经存在,则抛出异常 用户可以用 IF NOT EXIST 选项来忽略这个异常。EXTERNAL :该关键字可以让用户创建一个外部表,在创建表的同时指定一个指向实际数据的路径(LOCATION)。COMMENT :可以为表与字段增加描述。ROW FORMAT :用户在建表的时候可以自定义 SerDe....

《离线和实时大数据开发实战》(四)Hive 原理实践1
文章目录前言一、Hive 基本架构二、Hive SQLHive 关键概念1. Hive 数据库2. Hive 表3. 分区和桶( 1 )分区( 2 )分桶Hive DDL1. 创建表2. 修改表3. 删除表4. 插入表( 1 )向表中加载数据( 2 )将查询结果插入 HiveHive DML1. 基本的 select 操作2. join 表三、Hive SQL 执行原理图解四、小结前言我们都知道....

SmartNews:基于 Flink 加速 Hive 日表生产的实践
本文介绍了 SmartNews 利用 Flink 加速 Hive 日表的生产,将 Flink 无缝地集成到以 Airflow 和 Hive 为主的批处理系统的实践。详细介绍过程中遇到的技术挑战和应对方案,以供社区分享。主要内容为:项目背景问题的定义项目的目标技术选型技术挑战整体方案及挑战应对项目成果和展望后记GitHub 地址 https://github.com/apache/flink欢迎大....

Flink 1.11 与 Hive 批流一体数仓实践
导读:Flink 从 1.9.0 开始提供与 Hive 集成的功能,随着几个版本的迭代,在最新的 Flink 1.11 中,与 Hive 集成的功能进一步深化,并且开始尝试将流计算场景与Hive 进行整合。 本文主要分享在 Flink 1.11 中对接 Hive 的新特性,以及如何利用 Flink 对 Hive 数仓进行实时化改造,从而实现批流一体的目标。主要内容包括: · Flink ...

60TB 数据量的作业从 Hive 迁移到 Spark 在 Facebook 的实践
Facebook 经常使用分析来进行数据驱动的决策。在过去的几年里,用户和产品都得到了增长,使得我们分析引擎中单个查询的数据量达到了数十TB。我们的一些批处理分析都是基于 Hive 平台(Apache Hive 是 Facebook 在2009年贡献给社区的)和 Corona( Facebook 内部的 MapReduce 实现)进行的。Facebook 还针对包括 Hive 在内的多个内部数据....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。