
Scala+Spark+Hadoop+IDEA实现WordCount单词计数,上传并执行任务(简单实例-下)
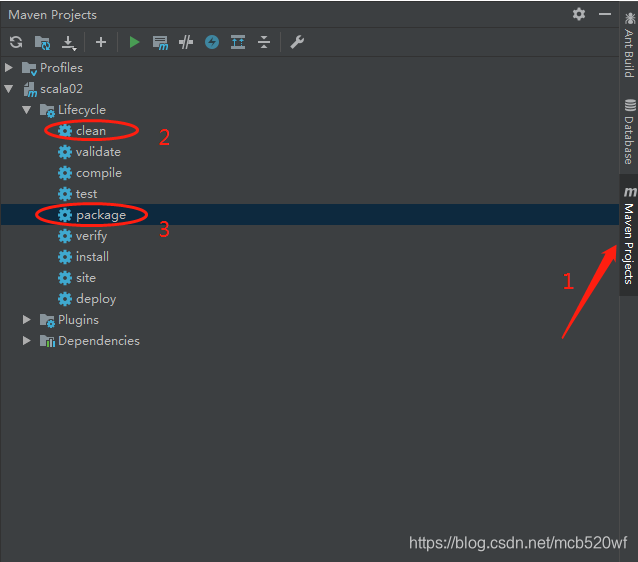
Scala+Spark+Hadoop+IDEA上传并执行任务 本文接续上一篇文章,已经在IDEA中执行Spark任务执行完毕,测试成功。 上文链接:Scala +Spark+Hadoop+Zookeeper+IDEA实现WordCount单词计数(简单实例) 一、打包 1.1 将setMaster注释掉 ...
Scala +Spark+Hadoop+Zookeeper+IDEA实现WordCount单词计数(简单实例-上)
IDEA+Scala +Spark实现wordCount单词计数-上 一、新建一个Scala的object单例对象,修改pom文件 (1)下面文章可以帮助参考安装 IDEA 和 新建一个Scala程序。 IntelliJ IDEA(最新)安装-破解详解--亲测可用 Intellij IDEA+Maven+Scala第一个程序 (2)...
运行Hadoop自带的wordcount单词统计程序
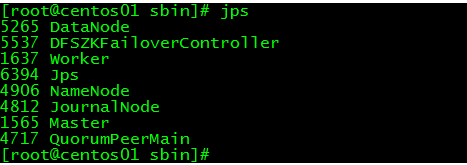
0.前言 前面一篇《Hadoop初体验:快速搭建Hadoop伪分布式环境》搭建了一个Hadoop的环境,现在就使用Hadoop自带的wordcount程序来做单词统计的案例。 http://www.linuxidc.com/Linux/2017-09/146694.htm 1.使用示例程序实现单词统计 ...
【大数据技术Hadoop+Spark】MapReduce之单词计数和倒排索引实战(附源码和数据集 超详细)
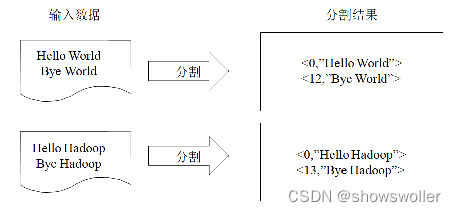
源码和数据集请点赞关注收藏后评论区留言私信~~~一、统计单词出现次数单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World。其主要功能是统计一系列文本文件中每个单词出现的次数程序解析首先MapReduce将文件拆分成splits,由于测试用的文件较小,只有二行文字,所以每个文件为一个split,并将文件按行分割形成<key, va....
【云计算与大数据计算】Hadoop MapReduce实战之统计每个单词出现次数、单词平均长度、Grep(附源码 )
需要全部代码请点赞关注收藏后评论区留言私信~~~下面通过WordCount,WordMean等几个例子讲解MapReduce的实际应用,编程环境都是以Hadoop MapReduce为基础一、WordCountWordCount用于计算文件中每个单词出现的次数,非常适合采用MapReduce进行处理,处理单词计数问题的思路很简单,在 Map阶段处理每个文本split中的数据,产生<word....
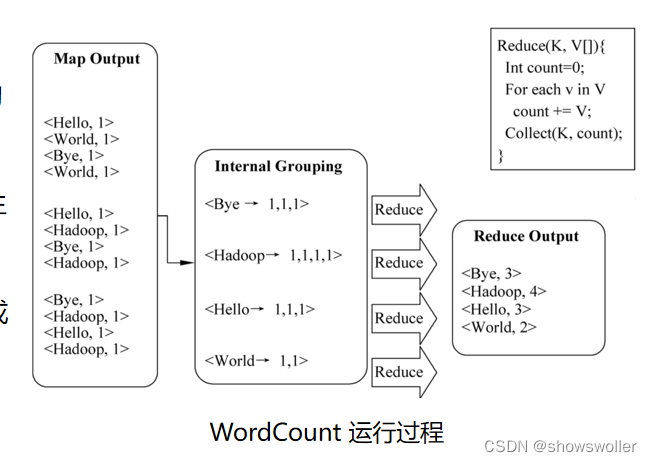
【Big Data】Hadoop--MapReduce经典题型实战(单词统计+成绩排序+文档倒插序列)
编辑 本文使用了3个经典案例进行MapReduce实战参考官方源码,代码风格较优雅解析详细一、IntroductionMapReduce是一个分布式运算程序的编程框架,核心功能是将用户写的业务逻辑代码和自身默认代码整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上其整体架构逻辑如下Map读取数据,进行简单数据整理Shuffle整合Map的数据Reduce计算处....
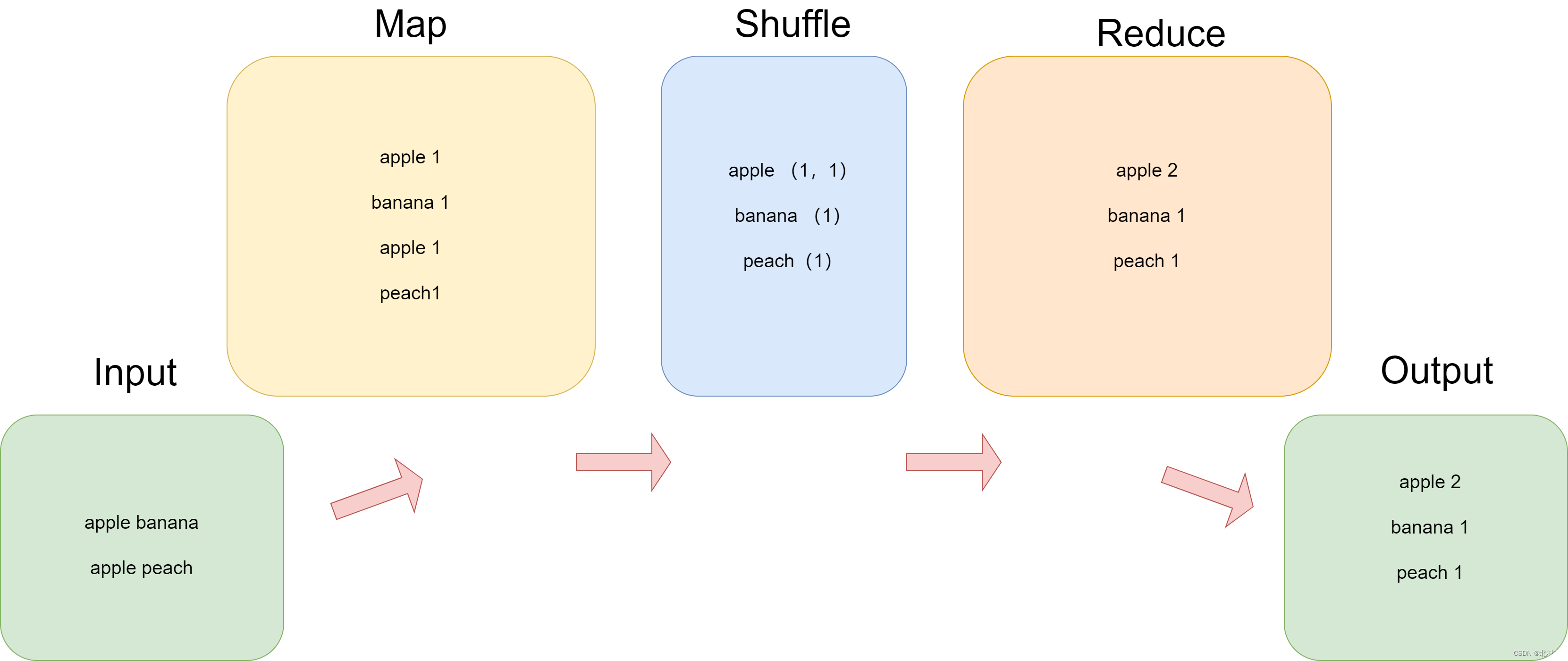
运行Hadoop自带的单词统计程序
Java,hadoop环境变量路径export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64export PATH=JAVAHOME/bin:JAVA_HOME/bin:JAVAHOME/bin:PATHexport CLASSPATH=.:JAVAHOME/lib/dt.jar:JAVA_HOME/lib/dt.jar:JAVAHOME/lib/dt....

单机版 hadoop 云平台(伪分布式)搭建 统计单词
1.首先需要配置java环境CentOS安装java jdk教程2.上传hadoop到/usr/local目录 并解压cd /usr/locallslinux上传下载文件教程3.配置hadoop环境目录vim /etc/profile#java environment export JAVA_HOME=/usr/local/jdk1.8.0_151 export JRE_HOME=/usr/lo....

Hadoop单词统计
1. 本地创建文本文件 [root@s166 fantj]# mkdir input [root@s166 fantj]# cd input/ [root@s166 input]# echo "hello fantj" > file1.txt [root@s166 input]# echo "hello hadoop" > file2.txt [root@s166 input]# e....
运行Hadoop自带的wordcount单词统计程序
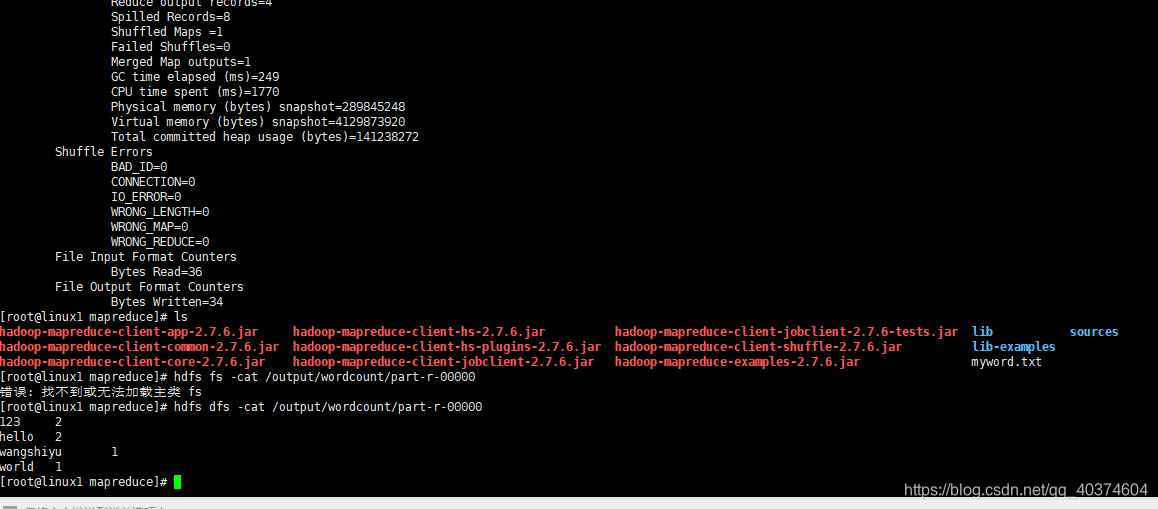
1.使用示例程序实现单词统计 (1)wordcount程序 wordcount程序在hadoop的share目录下,如下: 1 2 3 4 5 6 7 8 9 [root@leaf mapreduce]# pwd /usr/local/hadoop/share/hadoop/mapreduce [root@leaf mapreduce]#&...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop单词相关内容
hadoop您可能感兴趣
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop分布式
- hadoop系统
- hadoop存储
- hadoop解析
- hadoop大数据处理
- hadoop大数据
- hadoop集群
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop spark
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作