
如何将ApacheShardingSphere-Proxy与PolarDB多主架构结合使用
本文介绍Apache ShardingSphere-Proxy与PolarDB多主集群(Limitless)结合使用的最佳实践。
在挂载文件存储HDFS版的Hadoop集群上安装及使用Apache Tez
本文主要介绍在挂载文件存储 HDFS 版的Hadoop集群上安装及使用Apache Tez。
CentOS 7上集群化部署Apache Druid 0.22实时分析数据库(二)
修改了historical服务进程端口为18083,druid.processing.buffer.sizeBytes降至250M,druid.segmentCache.locations中maxSize降至20g,这些参数可以根据你的计算资源量进行放大调整。接着配置middleManager:vi /opt/druid/conf/druid/cluster/data/middleManager....
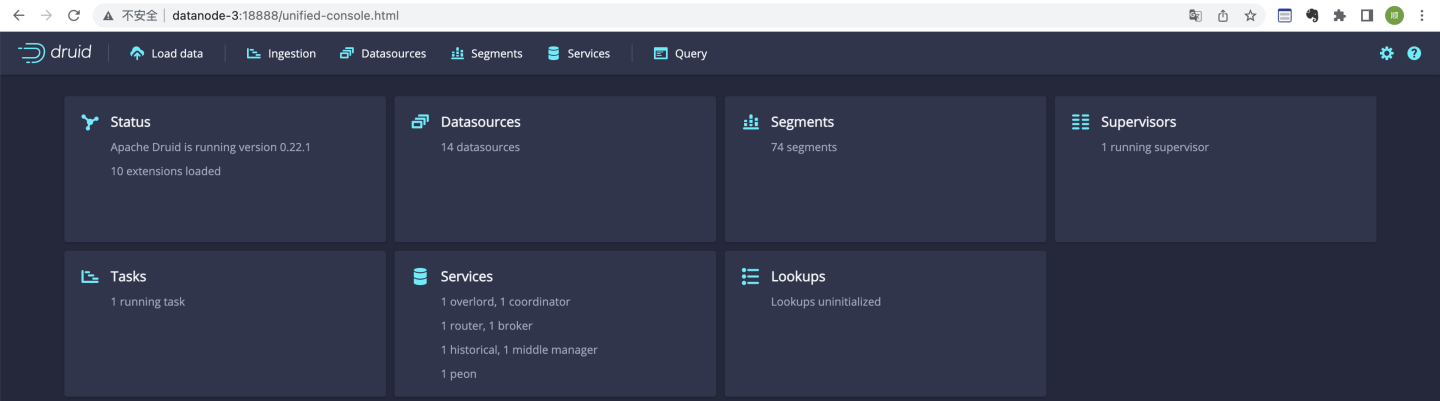
CentOS 7上集群化部署Apache Druid 0.22实时分析数据库(一)
部署准备Apache Druid依赖深度存储、元数据库和分布式协调器。深度存储主要是解决数据高可靠问题,也就是说,如果Druid数据节点的持久化数据出现丢失,可以从深度存储中恢复。深度存储可以使用本地文件、Hadoop HDFS、Amazon S3等方式,我们这里选择HDFS。元数据库存储集群元数据,包括Datasouce、Segments、Supervisors、Tasks、Rules等前期配....
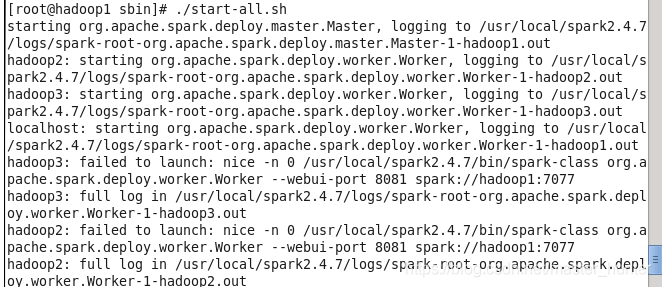
解决集群org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://hadoop1:7077问题
问题出现: 出现该问题的原因在于其他集群的profile并没有设置好:export JAVA_HOME=/usr/java/default export SPARK_HOME=/usr/local/spark2.4.7 export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin export.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache集群相关内容
- 高可用性Apache集群
- Apache安装配置集群
- 大数据Apache集群
- Apache集群模式
- Apache druid集群
- zookeeper Apache集群节点
- Apache集群节点
- zookeeper Apache集群
- zookeeper Apache集群验证
- Apache集群并发
- Apache节点集群
- Apache zookeeper集群
- Apache zookeeper集群模式
- Apache集群leader
- Apache zookeeper集群leader
- Apache zk集群模式
- Apache集群监控
- Apache负载均衡集群
- Apache standalone集群
- Apache jk集群
- Apache集群session共享
Apache您可能感兴趣
- Apache meetup
- Apache阿里云
- Apache doris
- Apache日志
- Apache教程
- Apache配置
- Apache技术
- Apache数据库
- Apache php7.1
- Apache php
- Apache flink
- Apache rocketmq
- Apache安装
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache hudi
- Apache实践
- Apache应用
- Apache web

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注