
SelectDB数据缓存
通过合理设置LRU和TTL策略,并利用缓存预热功能对指定的数据(Table或Partition)进行预热,可以有效地管理缓存数据,从而提升云数据库 SelectDB 版的访问速度。本文为您介绍云数据库 SelectDB 版的数据缓存功能。
Fluid数据缓存优化策略最佳实践
在计算与存储分离的架构下,使用Fluid数据缓存技术,能够有效解决在Kubernetes集群中访问存储系统数据时容易出现的高延迟及带宽受限问题,从而提升数据处理效率。本文从性能维度、稳定性维度、读写一致性维度介绍如何使用Fluid数据缓存策略。
实现应用Pod与缓存数据之间的亲和性调度
通过Fluid提供的数据缓存亲和性调度优化能力,您可以设置应用Pod上的亲和性配置,让应用Pod优先访问同节点、同可用区节点或同地域节点的缓存数据,从而提高应用Pod访问数据的效率。
通过控制台或者API方式使用数据缓存搭建一台“妙鸭相机”
本文以部署ModelScope社区的人物AIGC基础模型(ly261666/cv_portrait_model)搭建类似妙鸭相机的应用为例,演示如何使用数据缓存。通过数据缓存提前拉取模型数据,然后在创建应用实例时直接挂载模型数据,可以免去在实例中拉取模型数据的等待时间,加速应用部署。
SelectDB数据缓存的原理与使用方法_云数据库 SelectDB 版(SelectDB)
本文介绍云数据库 SelectDB 版中湖仓一体相关的数据缓存功能(File Cache),帮助您对外部数据源进行高效的联邦分析。
使用 Docker Compose 部署单机版 Redis:简单高效的数据缓存与存储
家人们啦!今天我们来介绍如何使用 docker-compose 部署单机版 Redis,这是一个简单高效的数据缓存与存储解决方案,广泛应用于Web应用、移动应用以及各类数据处理场景。我们过后几篇文章了将会介绍cluster和sentinel集群的部署。通过本文的指导,你将能够快速上手并体验 Redis 在你的应用中所带来的便捷性与高性能。废话不多说,让我们开始吧! 官方文档:https://r.....

面试:1~2亿条数据需要缓存,请问如何设计这个存储案例
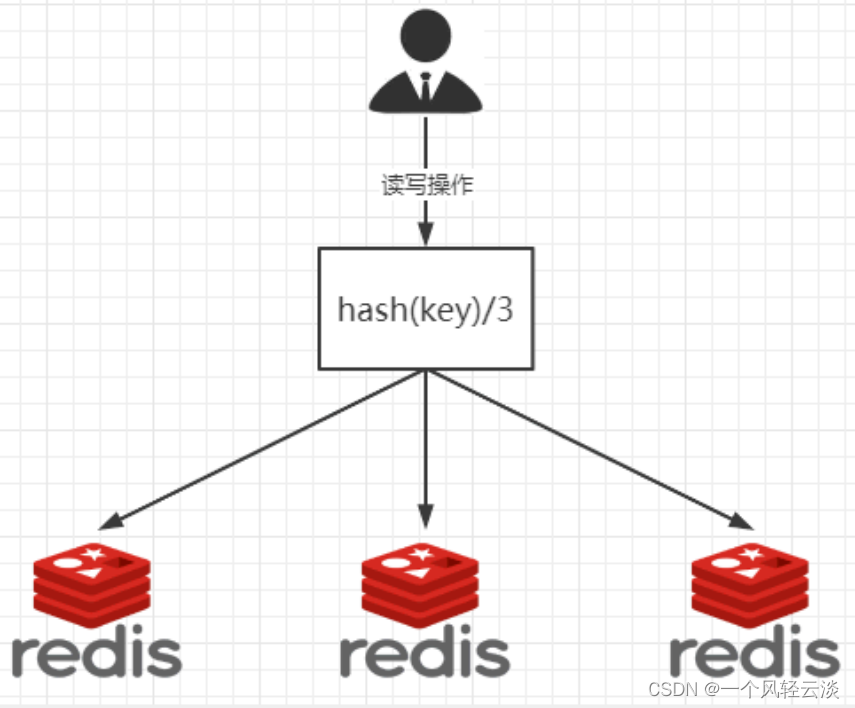
1~2亿条数据需要缓存,请问如何设计这个存储案例单机单台100%不可能,肯定是分布式存储用redis如何落地?上述问题阿里P6~P7工程案例和场景设计类必考题目, 一般业界有3种解决方案哈希取余分区2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
缓存更多数据相关
产品推荐
阿里云存储服务
阿里云存储基于飞天盘古2.0分布式存储系统,产品多种多样,充分满足用户数据存储和迁移上云需求。
+关注