
【数据挖掘】KNN算法详解及对iris数据集分类实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~K近邻(k-Nearest Neighbor Classification,KNN)算法是机器学习算法中最基础、最简单的算法之一,属于惰性学习法.惰性学习法和其他学习方法的不同之处在于它并不急于获得测试对象之前构造的分类模型,当接收一个训练集时,惰性学习法只是简单的存储或者稍微处理每个训练样本,直到测试对象出现才开始构造分类器,惰性学习法的一个重要优点....
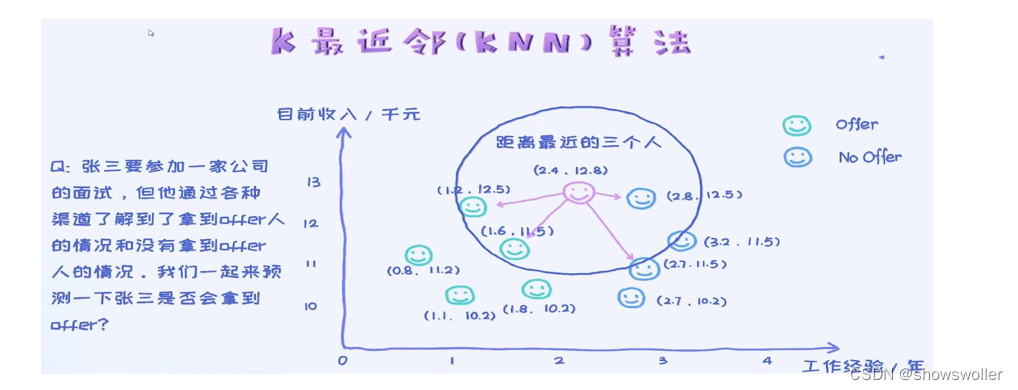
【数据挖掘】决策树中C4.5与CART算法讲解及决策树应用iris数据集实战(图文解释 附源码)
需要完整代码和PPT请点赞关注收藏后评论区留言私信~~~1:C4.5算法Quinlan在1993年提出了ID3的改进版本C4.5算法。它与ID3算法的不同主要有以下几点(1)分支指标采用增益比例,而不是ID3所使用的信息增益(2)按照数值属性值的大小对样本排序,从中选择一个分割点,划分数值属性的取值区间,从而将ID3的处理能力扩充到数值属性上来(3)将训练样本集中的位置属性值用最常用的值代替,或....

【数据挖掘】关联模式评估方法及Apriori算法超市购物应用实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~大部分关联规则挖掘算法都使用支持度-置信度框架。尽管最小支持度和置信度阈值可以排除大量无趣规则的探查,但仍然会有一些用户不感兴趣的规则存在。当使用低支持度阈值挖掘或挖掘长模式时,这种情况尤为严重强关联规则不一定是有趣的,并且只有用户才能够评判一个给定的规则是否有趣从关联分析到相关分析由于支持度和置信度还不足以过滤掉无趣的关联规则,因此,可以使用相关性度....

【Python机器学习】K-Means算法对人脸图像进行聚类实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~K-Mean算法,即 K 均值算法,是一种常见的聚类算法。算法会将数据集分为 K 个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”。算法步骤K-Means容易受初始质心的影响;算法简单,容易实现;算法聚类时,容易产生空簇;算法可能收敛到局部最小值。通过聚类可以实现:发现不同用户群体,从而可以实现精准营销;对文档进行划分;社交网络中,....

白盒攻击中FGM、FGSM、DeepFool算法在MNIST手写数字集中的实战(附源码)
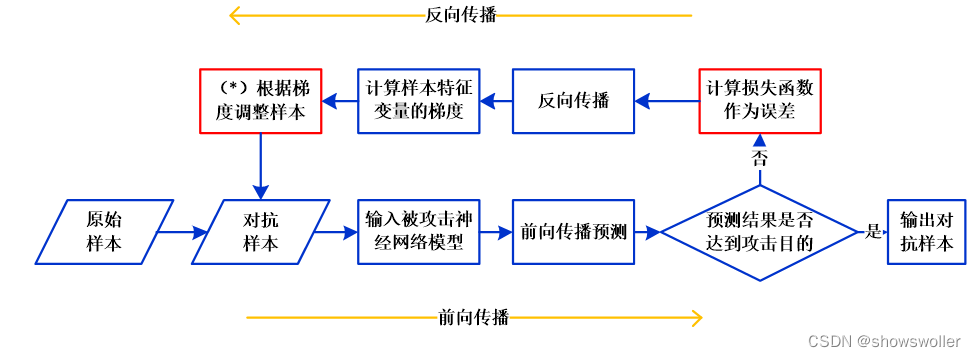
需要源码请点赞关注收藏后评论区留言私信~~~白盒攻击根据攻击者对模型的了解程度,对抗攻击可分为白盒攻击和黑盒攻击。白盒攻击是指攻击者掌握包括模型结构与系数在内的所有信息。黑盒攻击是指攻击者对模型结构与参数不了解,仅能够对模型进行输入试探以获得对应的输出响应。FGM算法算法流程图如下 在定向攻击时,误差是用前向传播的输出与攻击目标y_target进行比较计算得到的,因此,扰动的目标是使该误差变小,....
【Python强化学习】时序差分法Sarsa算法和Qlearning算法在冰湖问题中实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~时序差分算法时序差分法在一步采样之后就更新动作值函数Q(s,a),而不是等轨迹的采样全部完成后再更新动作值函数。在时序差分法中,对轨迹中的当前步的(s,a)的累积折扣回报G,用立即回报和下一步的(s^′,a^′)的折扣动作值函数之和r+γQ(s^′,a^′)来计算,即:G=r+γQ(s^′,a^′)在递增计算动作值函数时,用一个[0,1]之间的步长α来....
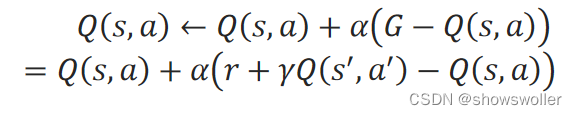
【Python机器学习】Mean Shift、Kmeans聚类算法在图像分割中实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~Mean Shift算法是根据样本点分布密度进行迭代的聚类算法,它可以发现在空间中聚集的样本簇。簇中心是样本点密度最大的地方。Mean Shift算法寻找一个簇的过程是先随机选择一个点作为初始簇中心,然后从该点开始,始终向密度大的方向持续迭代前进,直到到达密度最大的位置。然后在剩下的点里重复以上过程,找到所有簇中心。如何找到密度大的方向并前进多....
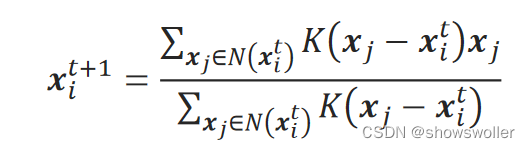
【Python机器学习】层次聚类AGNES、二分K-Means算法的讲解及实战演示(图文解释 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~层次聚类在聚类算法中,有一类研究执行过程的算法,它们以其他聚类算法为基础,通过不同的运用方式试图达到提高效率,避免局部最优等目的,这类算法主要有网格聚类和层次聚类算法网格聚类算法强调的是分批统一处理以提高效率,具体的做法是将特征空间划分为若干个网格,网格内的所有样本看成一个单元进行处理,网格聚类算法要与划分聚类或密度聚类算法结合使用,网格聚类算....

【Python机器学习】PCA降维算法讲解及二维、高维数据可视化降维实战(附源码 超详细)
需要全部代码请点赞关注收藏后评论区留言私信~~~维数灾难维数灾难是指在涉及到向量计算的问题中,当维数增加时,空间的体积增长得很快,使得可用的数据在空间中的分布变得稀疏,向量的计算量呈指数倍增长的一种现象。维数灾难涉及数值分析、抽样、组合、机器学习、数据挖掘和数据库等诸多领域。降维不仅可以减少样本的特征数量,还可以用来解决特征冗余(是指不同特征有高度相关性)等其他数据预处理问题。可视化并探索高维数....

【Python机器学习】聚类算法任务,评价指标SC、DBI、ZQ等系数详解和实战演示(附源码 图文解释)
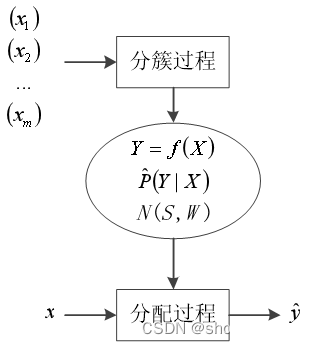
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、聚类任务设样本集S={x_1,x_2,…,x_m}包含m个未标记样本,样本x_i=(x_i^(1),x_i^(2),…,x_i^(n))是一个n维特征向量。聚类在分簇过程的任务是建立簇结构,即要将S划分为k(有的聚类算法将k作为需事先指定的超参数,有的聚类算法可自动确定k的值)个不相交的簇C_1,C_2,…,C_k,C_l∩C_l^′=∅且....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法更多源码相关

智能搜索推荐
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。
+关注