
seatunnel配置mysql2hive
SeaTunnel安装教程 # ====执行流程 # 下载,解压 # https://mirrors.aliyun.com/apache/seatunnel/2.3.8/?spm=a2c6h.25603864.0.0.2e2d3f665eBj1E # https://blog.csdn....
在Flink CDC中这种配置,会自动删除超过30天前的hive分区吗?
在Flink CDC中这种配置,会自动删除超过30天前的hive分区吗? --table-conf tag.automatic-creation='process-time' \ --table-conf tag.creation-period='daily' \ --table-conf tag.creation-delay='5 m' \ --table-conf part...
DataWorks通过脚本模式配置离线同步任务,从Hive同步数据到HBase,是参数位置不对吗?
DataWorks通过脚本模式配置离线同步任务,从Hive同步数据到HBase,读取hive时设置了参数,运行报错,是参数位置不对吗?
配置Hive使用Spark执行引擎
Hive引擎 概述 在Hive中,可以通过配置来指定使用不同的执行引擎。Hive执行引擎包括:默认MR、tez、spark MapReduce引擎: 早期版本Hive使用MapReduce作为执行引擎。MapReduce是Hadoop的一种计算模型,它通过将数据划分为小块并在集群上并行处理来完成计算任务。在MapReduce引擎中,Hive将HiveQL查询转换为一系列M...
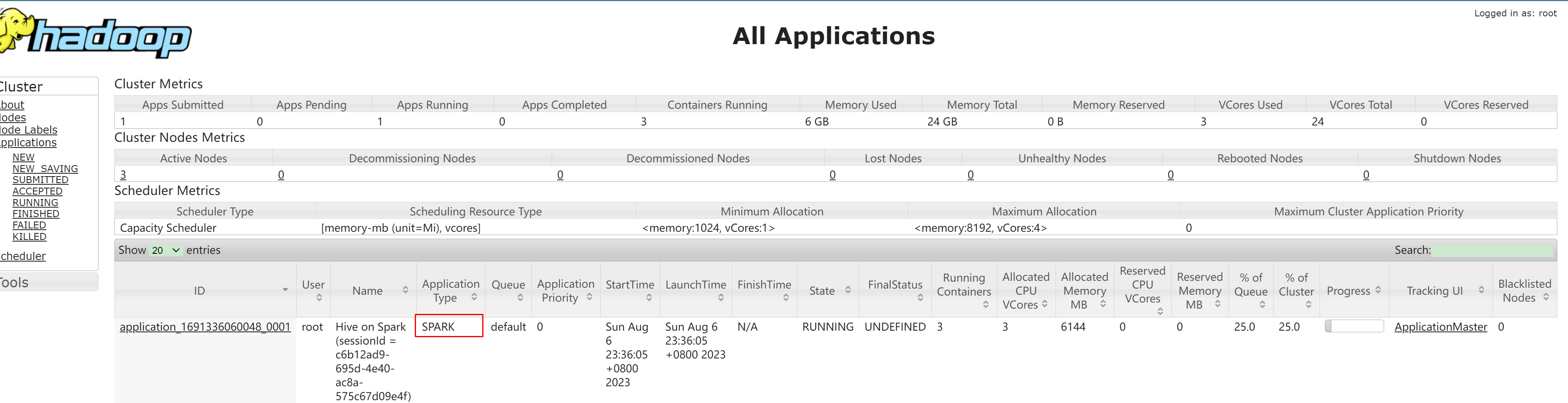
大数据平台 CDP 中如何配置 hive 作业的 YARN 队列以确保SLA?
大数据平台 CDP 中如何配置 hive 作业的 YARN 队列以确保SLA?大家知道,在生产环境的大数据集群中,在向资源管理器YARN提交作业时,我们一般会将作业提交到管理员指定的队列去执行,以利用 YARN 队列的资源隔离性确保作业能够获得足够的资源进行执行,从而确保SLA。1 CDH 中如何指定 HIVE 作业执行时的 YARN 队列?在以往的的大数据平台 CDH中:YARN 默认使用的资....
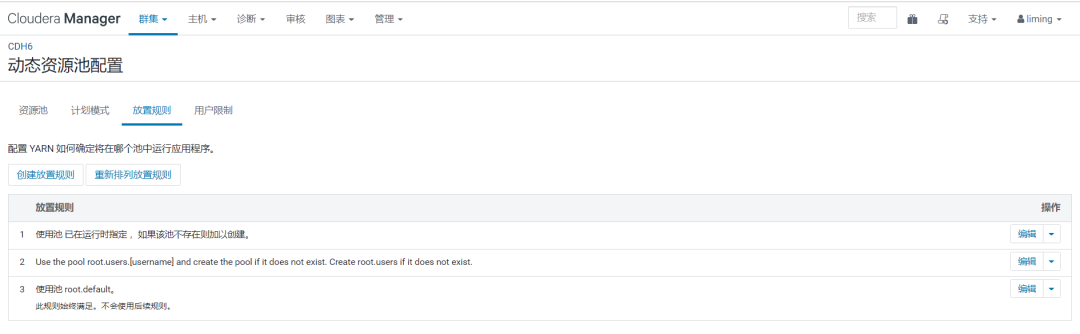
使用云上的Flink读取本地的HDFS,是否有什么配置,可以把读取HDFS的用户设置成hive ?
使用云上的Flink读取本地的HDFS,目前直接读取HDFS是通过Flink用户,是否什么配置,可以把读取HDFS的用户设置成hive或者hadoop?
DataWorks配置hive数据源的 离线任务,hive数据表清单获取不到一直转圈圈是咋回事?
DataWorks配置hive数据源的 离线任务,hive数据源联通测试是过的 但是 hive数据表清单获取不到一直转圈圈是咋回事?
配置开启Hive远程连接
Hive远程连接 要配置Hive远程连接,首先确保HiveServer2已启动并监听指定的端口 hive/bin/hiveserver2 检查 HiveServer2是否正在运行 # lsof -i:10000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 660 root 565u IPv6 899...
Flink CDC中这样配置,Hive可用,但是文件系统不能用。问题又回来了,怎么解决?
"Flink CDC中这样配置,Hive可用,但是文件系统不能用。问题又回来了,怎么解决?"
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
