
SPARK SQL中 Grouping sets转Expand怎么实现的(逻辑计划级别)
背景本文基于spark 3.1.2之前在做bug调试的时候遇到了expand的问题,在此记录一下分析运行该sql:create table test_a_pt(col1 int, col2 int,pt string) USING parquet PARTITIONED BY (pt); insert into table test_a_pt values(1,2,'20220101'),(3,....
SPARK Expand问题的解决(由count distinct、group sets、cube、rollup引起的)
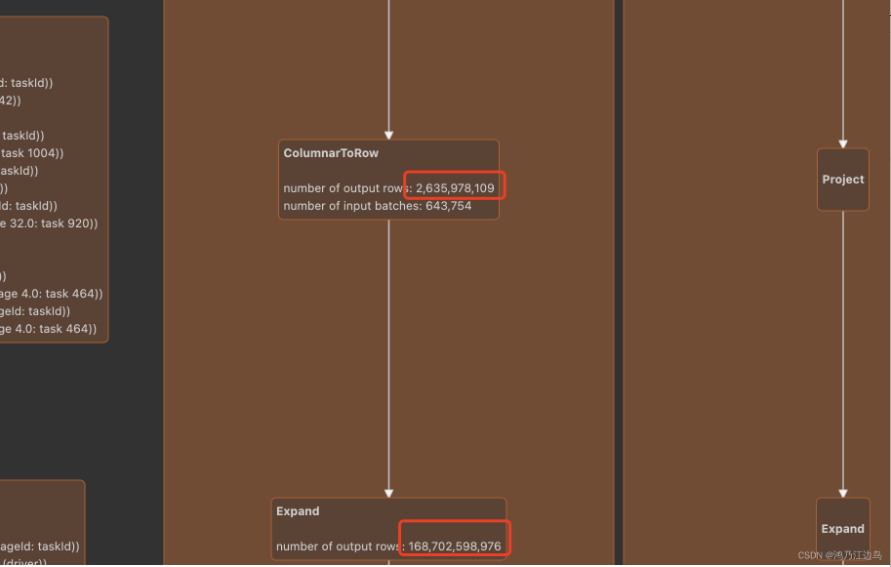
背景本文基于spark 3.1.2我们知道spark对于count(distinct)/group sets 以及cube、rollup的处理都是采用转换为Expand的方法处理,这样做的优点就是在数据量小的情况下,能有以空间换时间,从而达到加速的目的。但是弊端也是很明显,就是在数据量较大的情况下,而且expand的倍数达到上百倍或者千倍的时候,这任务运行的时间很长(这在数分中是非常常见的)。分....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark技术
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark任务
- apache spark调度
- apache spark yarn
- apache spark作业
- apache spark Hive
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark应用
- apache spark实战
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注