
优化Hadoop MapReduce性能的最佳实践
引言 Hadoop MapReduce是一个用于处理大规模数据集的软件框架,适用于分布式计算环境。虽然MapReduce框架本身具有很好的可扩展性和容错性,但在某些情况下,任务执行可能会因为各种原因导致性能瓶颈。本文将探讨如何通过调整配置参数和优化算法逻辑来提高MapReduce任务的效率。 MapReduce工作原理简述 MapReduce工作分为两个...
优化大数据处理:Java与Hadoop生态系统集成
引言 随着数据规模的快速增长,大数据处理成为现代信息技术领域的重要课题之一。本文将探讨如何通过优化Java与Hadoop生态系统的集成,实现高效、可扩展的大数据处理。 Java与Hadoop生态系统的基础 1. Hadoop生态系统概述 Hadoop是一个开源的分布式存储和计算框架,其核心组件包括HDFS(分布式文件系统)和MapReduce(分布式计算模型),此...
优化大数据处理:Java与Hadoop生态系统集成
优化大数据处理:Java与Hadoop生态系统集成 随着数据规模的快速增长,大数据处理成为现代信息技术领域的重要课题之一。本文将探讨如何通过优化Java与Hadoop生态系统的集成,实现高效、可扩展的大数据处理。 Java与Hadoop生态系统的基础 1. Hadoop生态系统概述 Hadoop是一个开源的分布式存储和计算框架,其核心组件包...
如何优化Hadoop集群的内存使用?
如何优化Hadoop集群的内存使用? 优化Hadoop集群的内存使用对于提高整体性能和处理能力至关重要。以下是一些具体的策略和建议: 合理配置JVM参数调整NameNode和DataNode的JVM内存大小:根据集群的大小和存储的数据量,合理设置NameNode和DataNode的JVM内存参数[^2^]。例如,可以通过调整H...
Centos优化Hadoop
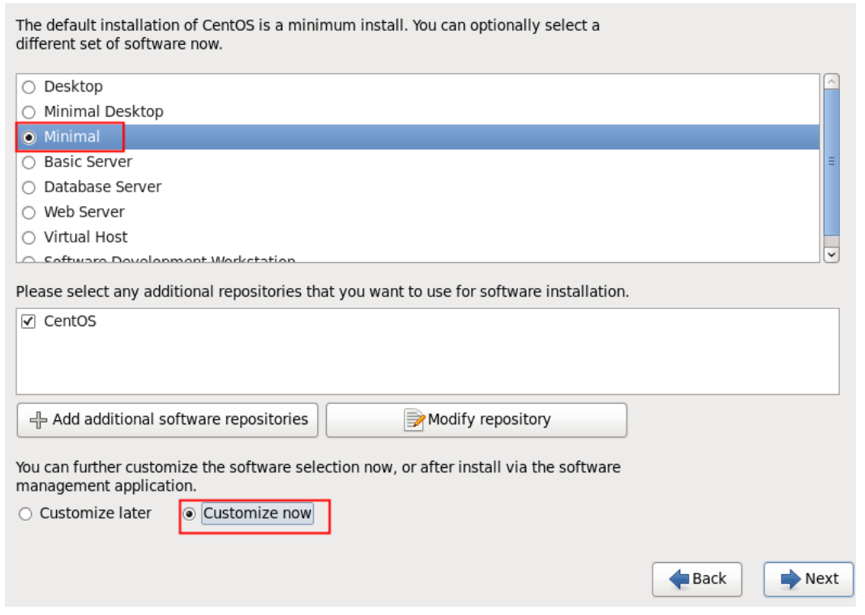
1、系统安装类型选择及自定义额外包组 进入如图 1-1 所示界面。 上半部分是系统定制的不同的系统安装类型选择项,默认是“ Desktop”,这里我们选择“ Minimal”,即最小化安装,下半部分是在上面系统安装类型确定后, 额外想添加的软件包组选择项,我们选择“ Customize now”即立即自定义。 图 1-1 系统安装包类型选择及自定义额外包组。 在下图 1-2 的自定义额外的包组.....
优化Hadoop Balancer运行速度
1.修改dfs.datanode.max.transfer.threads = 4096 (如果运行hbase的话建议为16384),指定用于在DataNode间传输block数据的最大线程数,老版本的对应参数为dfs.datanode.max.xcievers 2.修改dfs.datanode.balance.bandwidthPerSec =...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop您可能感兴趣
- hadoop集群管理
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop分布式
- hadoop系统
- hadoop存储
- hadoop解析
- hadoop大数据处理
- hadoop集群
- hadoop大数据
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop spark
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动