
选择业务场景
阿里云EMR针对不同业务场景提供了数据湖集群、数据分析集群、实时数据流集群、数据服务集群四类预定义业务场景。若您的业务需集成特定组合的组件,您可创建自定义集群,灵活组合EMR提供的组件,打造适配业务特性的大数据平台。本文将为您介绍这些集群的区别,帮助您快速选型。
与自建集群的对比优势
与自建Hadoop集群相比,开源大数据开发平台EMR提供弹性资源管理和自动化运维,降低运维复杂度,通过用户管理、数据加密和权限管理等为数据安全保驾护航,同时EMR集成了丰富的开源组件并打通开源生态与阿里云生态,便于快速搭建大数据处理和分析场景。
使用Hadoop命令操作OSS/OSS-HDFS
在使用阿里云EMR Serverless Spark的Notebook时,您可以通过Hadoop命令直接访问OSS或OSS-HDFS数据源。本文将详细介绍如何通过Hadoop命令操作OSS/OSS-HDFS。
大数据计算MaxCompute3.1.1 对hadoop安装的版本有没有特殊要求?
大数据计算MaxCompute3.1.1 对hadoop安装的版本有没有特殊要求?
【大数据】Hadoop下载安装及伪分布式集群搭建教程
1.概述 hadoop有三种安装模式 单机模式,只在一台机器上运行,存储用的本地文件系统而不是HDFS。 伪分布式模式,存储采用HDFS,名称节点和数据节点在同一台机器上。 分布式模式,标准的分布式集群。 做实验或者学习阶段选择伪分布式就好,本文将详细讲解在Linux搭建起一个伪分布式的hadoop集群。 2.环境准备 ...

![[大数据] mac 史上最简单 hadoop 安装过程](https://ucc.alicdn.com/pic/developer-ecology/okfcmqqjwxoec_2f6cbf8f324a4089ad542044bca478f0.png)
迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
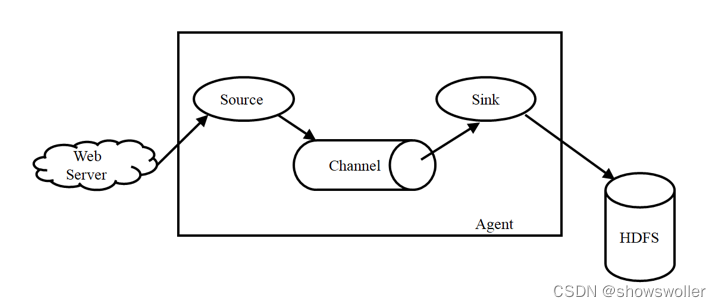
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:完成对日志数据的收集,分成transtion 和 event 打入到channel之中。2)Cha....
【大数据开发技术】实验01-Hadoop安装部署
Hadoop安装部署虚拟机数量:3系统版本:Centos 7.5Hadoop版本: Apache Hadoop 2.7.3主节点信息:操作系统:CentOS7.5软件包位置:/home/zkpk/tgz数据包位置:/home/zkpk/experiment从节点信息:操作系统:CentOS7.5软件包位置:/home/zkpk/tgz数据包位置:/home/zkpk/experiment从节点信....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop大数据相关内容
- hadoop spark大数据
- hadoop spark大数据协同
- 大数据hadoop环境
- 大数据学习hadoop
- 大数据hadoop
- 大数据hadoop分析
- 大数据spark模式hadoop
- 大数据模式hadoop
- 大数据部署hadoop
- 大数据hadoop mapreduce
- 大数据hadoop yarn
- 大数据hadoop节点
- 大数据hadoop笔记
- 大数据hadoop分发
- 大数据hadoop配置
- 大数据环境搭建hadoop
- 大数据组件hadoop
- hadoop入门大数据
- hadoop构建大数据分析
- hadoop概述大数据
- hadoop构建大数据
- hadoop系统大数据
- 大数据hadoop spark
- 大数据maxcompute hadoop
- 阿里巴巴大数据hadoop系统
- 大数据hadoop系统
- 大数据hadoop集成
- 大数据java hadoop
- hadoop大数据工具
- 大数据技术hadoop
hadoop更多大数据相关
- 大数据hadoop集群搭建
- hadoop系统大数据技术
- hadoop大数据入门
- 大数据hadoop伪分布
- 大数据hadoop安装教程
- 大数据hadoop教程
- 大数据hadoop入门
- 大数据hadoop简介
- 大数据hadoop mapreduce编程
- 大数据hadoop实践
- 大数据开发hadoop
- 大数据hadoop编程
- 大数据面试hadoop
- 大数据hadoop分布式
- 大数据实战hadoop
- 大数据hadoop开发
- 大数据实践hadoop
- 大数据hadoop应用
- 大数据面试题百日hadoop
- 大数据hadoop原理
- 大数据开发hadoop安装
- 大数据hadoop hive
- hadoop分布式大数据
- 大数据hadoop部署
- 大数据hadoop hbase
- 大数据hadoop运行
- 大数据hadoop技术
- 大数据框架hadoop
- 大数据环境hadoop
- 大数据hadoop命令
hadoop您可能感兴趣
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop技术
- hadoop集群管理
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop分布式
- hadoop集群
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作
- hadoop apache