
数据湖查询加速:利用高性能缓存提升查询性能
云原生数据仓库 AnalyticDB MySQL 版推出了湖存储加速(LakeCache)功能,能够将OSS中的热点文件缓存在NVMe SSD高性能存储介质上,提高OSS数据的读取效率。该功能主要适用于需要大量带宽,且数据重复读的场景,例如,多个分析人员需要查询同一份数据。本文主要介绍湖存储加速功能的优势、应用场景以及使用方法。
Spark SQL交互式查询
如果您需要以交互式方式执行Spark SQL,可以指定Spark Interactive型资源组作为执行查询的资源组。资源组的资源量会在指定范围自动扩缩容,在满足您交互式查询需求的同时还可以降低使用成本。本文为您详细介绍如何通过控制台、Hive JDBC、PyHive、Beeline、DBeaver等客户端工具实现Spark SQL交互式查询。
如何通过主外键约束提升JOIN查询性能
本文介绍如何使用主键(PRIMARY KEY)与外键(FOREIGN KEY)之间的约束关系来优化查询计划,消除多余的JOIN操作。
设置交互式查询的优先级队列与队列并发数
为了更细致地控制查询并发数,云原生数据仓库 AnalyticDB MySQL 版的Interactive型资源组提供了优先级队列的能力。每个资源组都有自己的一组优先级队列,包括LOWEST队列、LOW队列、NORMAL队列和HIGH队列。您可以设置查询的优先级,使不同查询进入不同的优先级队列,并通过修改队列并发数来对查询进行限流或放大并发。本文介绍如何设置查询的优先级,以及如何设置队列的并发数。
Mysql 分组查询取max 那条记录其他字段
需求描述:现有有需求要按类型分组,查询出每一分组最近的一条记录,返回字段包含id,定时任务执行时间(start_time)和任务id(job_id)。SELECT id, MAX(start_time) AS startTime,job_id AS jobId FROM `sta_task_alarm` GROUP BY `job_id`;问题描述:上面这个SQL查询出来的id 并不是我们想要的....
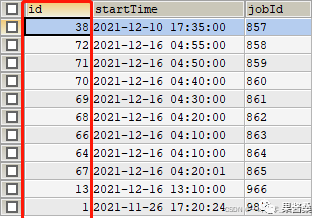
MySQL查询,MAX()+ GROUP BY?mysql
愚蠢的SQL问题。我有一个这样的表(“ pid”是自动递增的主列) CREATE TABLE theTable ( pid INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP, cost INT UNSIGNED NOT NULL, rid INT NOT NULL, ) .....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云数据库 RDS MySQL 版查询相关内容
- 阿里云云数据库 RDS MySQL 版查询
- polardb云数据库 RDS MySQL 版查询
- 云数据库 RDS MySQL 版查询性能
- 云数据库 RDS MySQL 版优化查询性能
- 云数据库 RDS MySQL 版优化查询
- 索引查询云数据库 RDS MySQL 版
- 云数据库 RDS MySQL 版分析查询
- 云数据库 RDS MySQL 版查询工具
- 云数据库 RDS MySQL 版慢日志查询
- 云数据库 RDS MySQL 版日志查询
- 云数据库 RDS MySQL 版查询类型
- 云数据库 RDS MySQL 版查询数据
- 云数据库 RDS MySQL 版字段查询
- 云数据库 RDS MySQL 版查询调优
- 云数据库 RDS MySQL 版查询性能调优
- 云数据库 RDS MySQL 版索引查询性能
- 云数据库 RDS MySQL 版查询实战
- 云数据库 RDS MySQL 版索引查询
- 优化云数据库 RDS MySQL 版索引查询
- 优化云数据库 RDS MySQL 版查询性能
- 云数据库 RDS MySQL 版索引策略查询
- 云数据库 RDS MySQL 版redis查询
- 云数据库 RDS MySQL 版查询解决方法
- 云数据库 RDS MySQL 版查询排序分组
- 云数据库 RDS MySQL 版查询聚合
- 云数据库 RDS MySQL 版查询排序分页
- 云数据库 RDS MySQL 版查询分页
- 云数据库 RDS MySQL 版查询分组
- 云数据库 RDS MySQL 版查询报错
- 云数据库 RDS MySQL 版查询select
云数据库 RDS MySQL 版更多查询相关
- 查询云数据库 RDS MySQL 版进程
- 云数据库 RDS MySQL 版脚本查询
- 云数据库 RDS MySQL 版sql查询
- 云数据库 RDS MySQL 版主键查询
- 连接云数据库 RDS MySQL 版查询
- 云数据库 RDS MySQL 版查询自定义
- 云数据库 RDS MySQL 版查询字母
- 云数据库 RDS MySQL 版查询字段
- 云数据库 RDS MySQL 版set查询
- 云数据库 RDS MySQL 版索引优化查询
- 云数据库 RDS MySQL 版数据库查询
- 云数据库 RDS MySQL 版查询索引
- 云数据库 RDS MySQL 版查询日志
- 云数据库 RDS MySQL 版查询语法
- 云数据库 RDS MySQL 版查询连接
- 测试云数据库 RDS MySQL 版查询
- 云数据库 RDS MySQL 版查询分析
- 云数据库 RDS MySQL 版查询信息
- 云数据库 RDS MySQL 版复合查询
- 云数据库 RDS MySQL 版学习笔记查询
- 云数据库 RDS MySQL 版入门查询
- 云数据库 RDS MySQL 版并行查询
- 云数据库 RDS MySQL 版日期查询
- 云数据库 RDS MySQL 版查询模式
- 云数据库 RDS MySQL 版聚合查询
- 云数据库 RDS MySQL 版语法查询
- 云数据库 RDS MySQL 版查询解析
- 软件测试云数据库 RDS MySQL 版面试查询
- 云数据库 RDS MySQL 版约束查询
- 云数据库 RDS MySQL 版查询多表查询
云数据库 RDS MySQL 版您可能感兴趣
- 云数据库 RDS MySQL 版仓库
- 云数据库 RDS MySQL 版yum
- 云数据库 RDS MySQL 版bufferpool
- 云数据库 RDS MySQL 版redo
- 云数据库 RDS MySQL 版undo
- 云数据库 RDS MySQL 版log
- 云数据库 RDS MySQL 版binlog
- 云数据库 RDS MySQL 版yashandb
- 云数据库 RDS MySQL 版验证
- 云数据库 RDS MySQL 版生产环境
- 云数据库 RDS MySQL 版数据库
- 云数据库 RDS MySQL 版数据
- 云数据库 RDS MySQL 版安装
- 云数据库 RDS MySQL 版sql
- 云数据库 RDS MySQL 版同步
- 云数据库 RDS MySQL 版连接
- 云数据库 RDS MySQL 版mysql
- 云数据库 RDS MySQL 版报错
- 云数据库 RDS MySQL 版配置
- 云数据库 RDS MySQL 版rds
- 云数据库 RDS MySQL 版索引
- 云数据库 RDS MySQL 版flink
- 云数据库 RDS MySQL 版cdc
- 云数据库 RDS MySQL 版表
- 云数据库 RDS MySQL 版优化
- 云数据库 RDS MySQL 版实例
- 云数据库 RDS MySQL 版备份
- 云数据库 RDS MySQL 版操作
- 云数据库 RDS MySQL 版linux
- 云数据库 RDS MySQL 版polardb

