
查询管理与分析
EMR StarRocks Manager针对您提交的查询(Query)记录提供诊断与分析的能力,能够对您提交的SQL查询进行详细记录和分析。它不仅支持展示所有执行的SQL任务记录,还支持慢查询分析,重点关注时间消耗较长的查询,以帮助您识别性能瓶颈,优化查询效率。
在EMR集群运行TPC-DS Benchmark
TPC-DS是大数据领域最为知名的Benchmark标准。阿里云E-MapReduce多次刷新TPC-DS官方最好成绩,并且是第一个通过认证的可运行TPC-DS 100 TB的大数据系统。本文介绍如何在EMR集群完整运行TPC-DS的99个SQL,并得到最佳的性能体验。
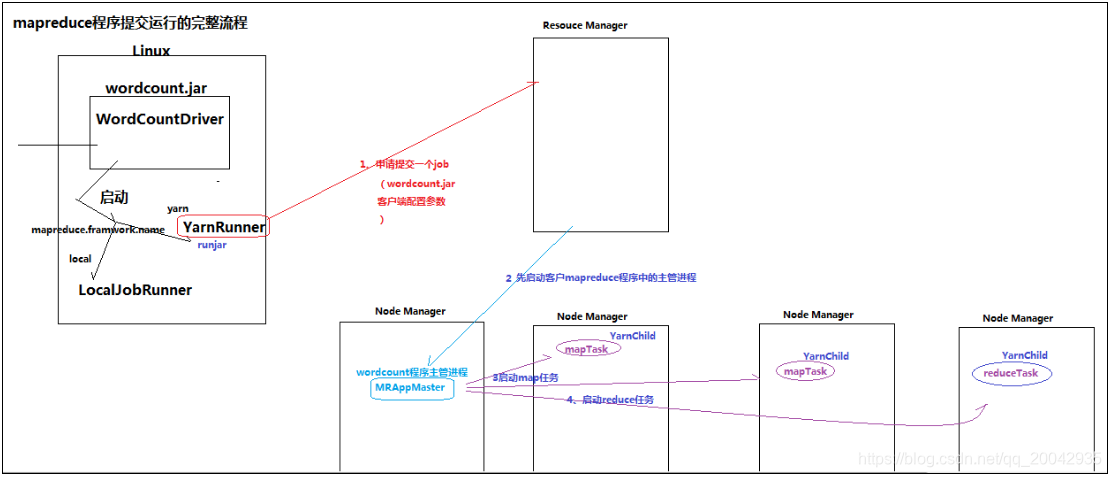
23 MAPREDUCE程序运行模式
本地运行模式1)mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行2)而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上3)怎样实现本地运行?写一个程序,不要带集群的配置文件(本质是你的mr程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname参数)。4)本地模式....
如何使用Arm节点运行Spark作业_EMR on ACK_开源大数据平台 E-MapReduce(EMR)
EMR on ACK默认部署在X86架构的节点上,您也可以通过配置,将Spark作业运行在Arm类型的弹性容器实例(ECI)上。本文为您介绍如何使用Arm节点运行Spark作业。
Dataphin项目绑定的计算引擎为CDH6时,代码运行报错:\"Filedoesnotexist:hdfs://domain_name:PORT/user/yarn/mapreduce/mr-framework/3.0.0-cdh6.3.2-mr-framework.tar.gz\"
问题描述Dataphin项目绑定的计算引擎为CDH6,代码运行报错“ Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. File does not exist: hdfs://domai...
2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算。 Map作一些,数据的局部处理和打散工作。 Reduce作一些,数据的汇总工作。 这是之前的,weekend110的hdfs输入流之源码分析。现在,全部关闭断点。 //4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key类型,VALUE是输入...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce hadoop
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务
