E-MapReduce集群如何设置task节点中的nodemanger不参与集群中任务的计算只...
E-MapReduce集群如何设置task节点中的nodemanger不参与集群中任务的计算只做spark任务的提交作业计算由core节点参与进行
阿里云E-MapReduce集群不同计算引擎sleep task使用笔记
1. 概述需求:日常在E-MapReduce集群中进行相关测试,验证一些切换或变更是否会影响业务的运行导致任务failed。所以需要在测试集群中运行指定资源数(vcore及memory)或者指定运行时间的任务。目前用到MapReduce和spark任务两种,其余的持续更新补充中……2. mapreduce官方提供的test jar,可以通过如下命令找到该测试jar包# 找到环境变量中的hadoo....
hadoop mapreduce运行job task报OutOfMemoryError错误
hadoop mapreduce运行job task报OutOfMemoryError错误java.lang.OutOfMemoryError: GC overhead limit exceeded at java.lang...
Yarn源码分析之MapReduce作业中任务Task调度整体流程(一)
v2版本的MapReduce作业中,作业JOB_SETUP_COMPLETED事件的发生,即作业SETUP阶段完成事件,会触发作业由SETUP状态转换到RUNNING状态,而作业状态转换中涉及作业信息的处理,是由SetupCompletedTransition来完成的,它主要做了四件事: &...
MapReduce源码分析之Task中关于对应TaskAttempt存储Map方案的一些思考
我们知道,MapReduce有三层调度模型,即Job——>Task——>TaskAttempt,并且: 1、通常一个Job存在多个Task,这些Task总共有Map Task和Redcue Task两种大的类型(为简化描述,Map-Only作业、JobSetup Task等复...
mapreduce出现大量task被KILLED_UNCLEAN的3个原因
Request received to kill task 'attempt_201411191723_2827635_r_000009_0' by user ------- Task has been KILLED_UNCLEAN by the user 原因如下: 1.An impatient user (armed with "mapred job -kill-task" command.....
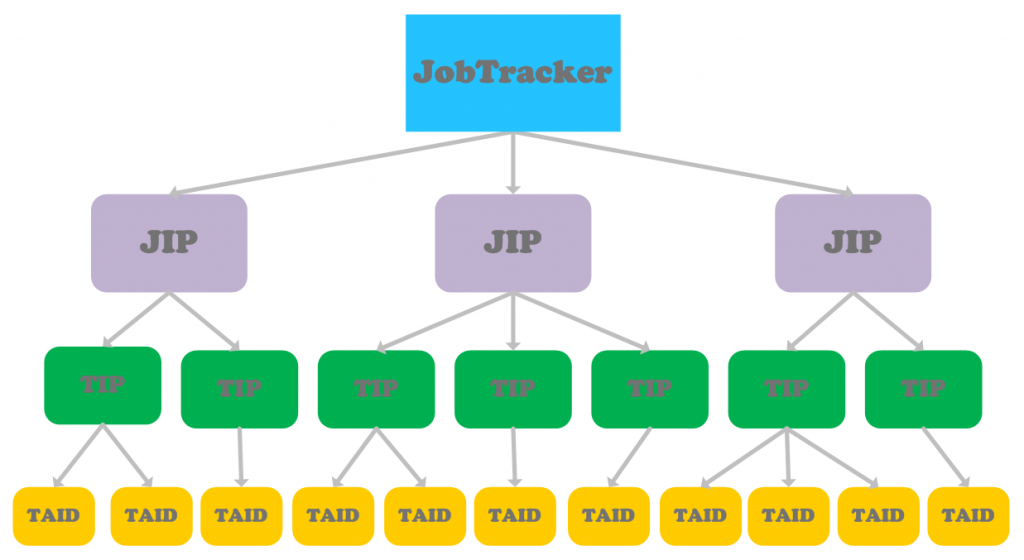
MapReduce V1:JobTracker端Job/Task数据结构
我们基于Hadoop 1.2.1源码分析MapReduce V1的处理流程。在MapReduce程序运行的过程中,JobTracker端会在内存中维护一些与Job/Task运行相关的信息,了解这些内容对分析MapReduce程序执行流程的源码会非常有帮助。 在编写MapReduce程序时,我们是以Job为单位进行编程处理,一个应用程序可能由一组Job组成,而MapReduce框架给我们暴露的只是....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce task相关内容
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce hadoop
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式