
基于Dify +Ollama+ Qwen2 完成本地 LLM 大模型应用实战
本文原文链接 尼恩:LLM大模型学习圣经PDF的起源 在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。 经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。 然而,其中一个成功案例,是一个9年经验...

LLM-05 大模型 15分钟 FineTuning 微调 ChatGLM3-6B(微调实战1) 官方案例 3090 24GB实战 需22GB显存 LoRA微调 P-TuningV2微调
续接上节 我们的流程走到了,环境准备完毕。 装完依赖之后,上节结果为: 介绍LoRA LoRA原理 LoRA的核心思想是在保持预训练模型的大部分权重参数不变的情况下,通过添加额外的网络层来进行微调。这些额外的网络层通常包括两个线性层,一个用于将数据从较高维度降到...

LLM-04 大模型 15分钟 FineTuning 微调 ChatGLM3-6B(准备环境) 3090 24GB实战 需22GB显存 LoRA微调 P-TuningV2微调
背景介绍 ChatGLM3是由智谱AI和清华大学KEG实验室联合开发的一款新一代对话预训练模型。这个模型是ChatGLM系列的最新版本,旨在提供更流畅的对话体验和较低的部署门槛。ChatGLM3-6B是该系列中的一个开源模型,它继承了前两代模型的优秀特性,并引入了一些新的功能和改进。 基础模型性能提升:ChatGLM3-6B基于更多样的训练数据、更充分的训练步数和更合理...

LLM-03 大模型 15分钟 FineTuning 微调 GPT2 模型 finetuning GPT微调实战 仅需6GB显存 单卡微调 数据 10MB数据集微调
参考资料 GPT2 FineTuning OpenAI-GPT2 Kaggle short-jokes 数据集 Why will you need fine-tuning an LLM? LLMs are generally trained on public data with no specific focus. Fine-tuning is a cr...

初识langchain:LLM大模型+Langchain实战[qwen2.1、GLM-4]+Prompt工程
初识langchain:LLM大模型+Langchain实战[qwen2.1、GLM-4]+Prompt工程 1.大模型基础知识 大模型三大重点:算力、数据、算法,ReAct (reason推理+act行动)--思维链 Langchain会把上述流程串起来,通过chain把多个算法模型串联起来 Langchain的 I/O系统,负责输入输出管理【文件形式加载提示词】 ...
![初识langchain:LLM大模型+Langchain实战[qwen2.1、GLM-4]+Prompt工程](https://ucc.alicdn.com/fnj5anauszhew_20240719_85e2ec2d8f98458dbd7eaa93b64fdf7e.png)
LLM 大模型学习必知必会系列(十三):基于SWIFT的VLLM推理加速与部署实战
LLM 大模型学习必知必会系列(十三):基于SWIFT的VLLM推理加速与部署实战1.环境准备GPU设备: A10, 3090, V100, A100均可.#设置pip全局镜像 (加速下载) pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ #安装ms-swift pip install 'ms-swi....

LLM 大模型学习必知必会系列(十一):大模型自动评估理论和实战以及大模型评估框架详解
LLM 大模型学习必知必会系列(十一):大模型自动评估理论和实战以及大模型评估框架详解 0.前言 大语言模型(LLM)评测是LLM开发和应用中的关键环节。目前评测方法可以分为人工评测和自动评测,其中,自动评测技术相比人工评测来讲,具有效率高、一致性好、可复现、鲁棒性好等特点,逐渐成为业界研究的重点。 模型的自动评测技术可以分为rule-based和model-based两大类: ru...

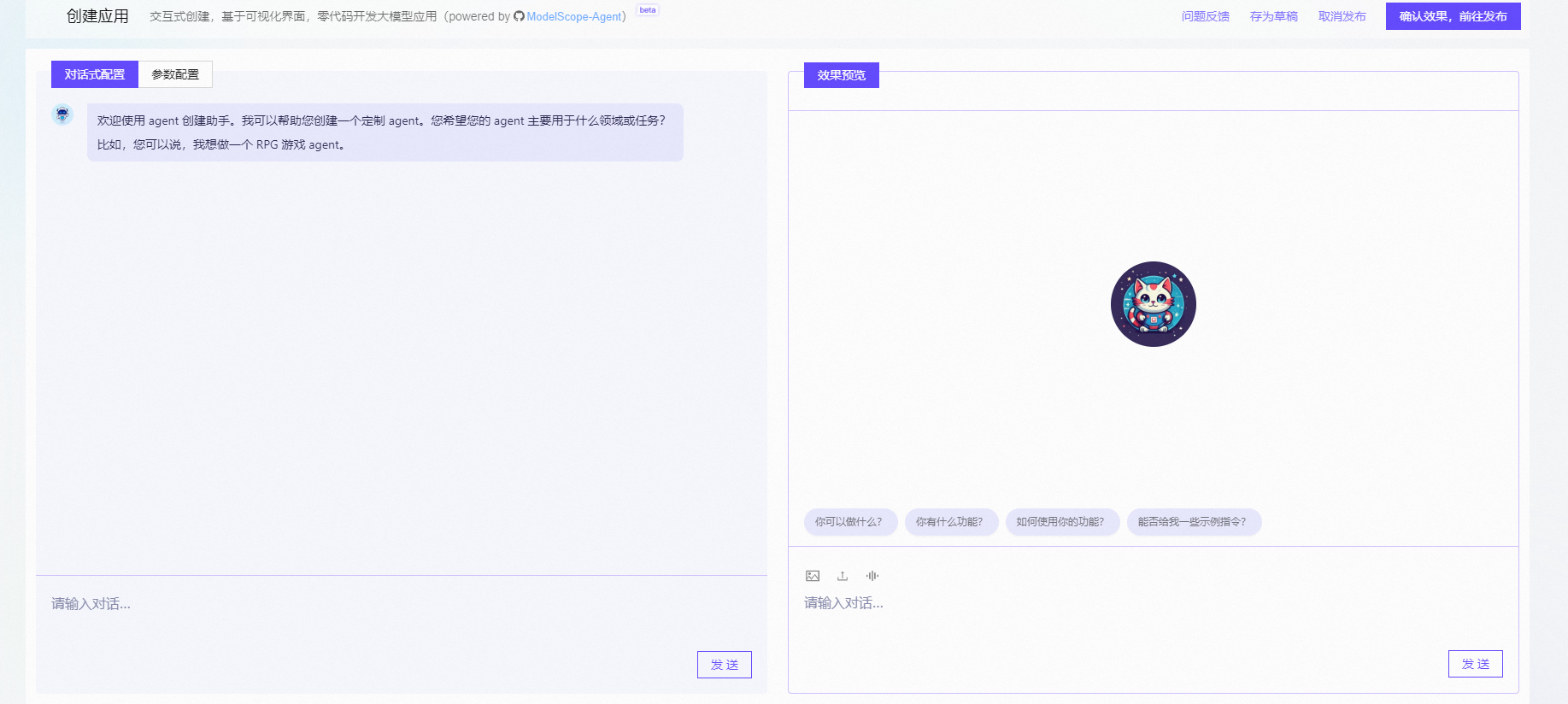
LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战
LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战 0.前言 Modelscope 是一个交互式智能体应用基于ModelScope-Agent,用于方便地创建针对各种现实应用量身定制智能体,目前已经在生产级别落地。AgentFabric围绕可插拔和可定制的LLM构建,并增强了指令执行、额外知识检索和利用外部工具的能力。AgentFabric提...
LLM 大模型学习必知必会系列(二):提示词工程-Prompt Engineering 以及实战闯关
LLM 大模型学习必知必会系列(二):提示词工程-Prompt Engineering 以及实战闯关 prompt(提示词)是我们和 LLM 互动最常用的方式,我们提供给 LLM 的 Prompt 作为模型的输入,并希望 LLM 反馈我们期待的结果。 虽然 LLM 的功能非常强大,但 LLM 对提示词(prompt)也非常敏感。这使得提示词工程成为一项需要培养的重要技能。 推荐使用环境:通义...
基于MaxFrame实现大模型(LLM)数据处理
随着人工智能的发展,许多业务和数据分析可以基于大语言模型(LLM)进行广泛的应用,而数据处理是LLM开发尤为重要的一环,数据质量的好坏直接影响大模型训练、推理的最终效果。相较于昂贵的GPU资源,MaxCompute的海量弹性CPU资源能够成为LLM海量数据处理的资源基础,而MaxFrame分布式计算能力可以帮助您更加高效、便捷地完成LLM数据处理工作。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。