
大数据-89 Spark 集群 RDD 编程-高阶 编写代码、RDD依赖关系、RDD持久化/缓存
点一下关注吧!!!非常感谢!!持续更新!!!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume&...

大数据-46 Redis 持久化 RDB AOF 配置参数 混合模式 具体原理 触发方式 优点与缺点
点一下关注吧!!!非常感谢!!持续更新!!!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume&...
大数据-45 Redis 持久化概念 RDB AOF机制 持久化原因和对比
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (正在更新…) 章节内容 上节完成...
大数据-41 Redis 类型集合(2) bitmap位操作 geohash空间计算 stream持久化消息队列 Z阶曲线 Base32编码
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop HDFS MapReduce Hive Flume Sqoop Zookeeper HBase Redis (正在更新) 章节内容 上一节我们完成了如下的内容: string 类型 list 类型...

大数据Spark RDD持久化和Checkpoint
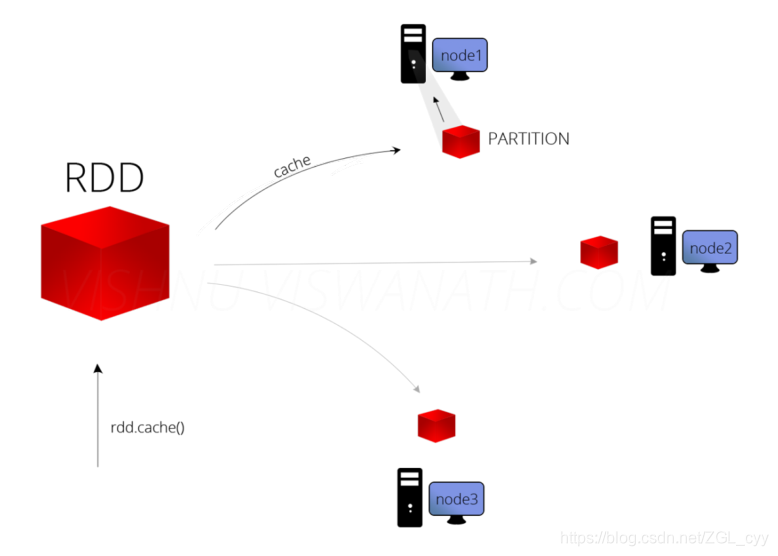
1 缓存函数在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。可以将RDD数据直接缓存到内存中,函数声明如下:但是实际项目中,不会直接使用上述的缓存函数,RDD数据量往往很多,内存放不下的。在实际的项目中缓存RDD数据时,往往使用如下函数,依据具体的业务....
《Spark与Hadoop大数据分析》——3.5 持久化与缓存
3.5 持久化与缓存 Spark 的一个独特功能是在内存中持久化 RDD。你可以使用 persist 或 cache 变换来持久化 RDD,如下所示: 上述两个语句都是相同的,并且会在 MEMORY_ONLY 存储级别缓存数据。它们的区别在于:cache 是指 MEMORY_ONLY 存储级别,而 persist 可以根据需要选择不同的存储级别,如下表所示。当第一次使用动作来进行计算时,它将保.....
《Spark与Hadoop大数据分析》一一3.5 持久化与缓存
本节书摘来自华章计算机《Spark与Hadoop大数据分析》一书中的第3章,第3.5节,作者:文卡特·安卡姆(Venkat Ankam) 更多章节内容可以访问云栖社区“华章计算机”公众号查看。 3.5 持久化与缓存 Spark 的一个独特功能是在内存中持久化 RDD。你可以使用 persist 或 cache 变换来持久化 RDD,如下所示: 上述两个语句都是相同的,并且会在 MEMORY_ON....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute持久化相关内容
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute风险评估
- 云原生大数据计算服务 MaxCompute决策
- 云原生大数据计算服务 MaxCompute供应链
- 云原生大数据计算服务 MaxCompute可视化
- 云原生大数据计算服务 MaxCompute智能
- 云原生大数据计算服务 MaxCompute企业
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里巴巴
- 云原生大数据计算服务 MaxCompute元数据
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台

