
【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件夹scala,界面如下:6) 将文件夹scala设置成Source Root,界面如下:7) 新建....
【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、RDD的创建Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。1、从文件系统加载数据创建RDD从运行结果反馈的信息可以看出,wordfile是一个String类型的RDD,或者以后可以简单....
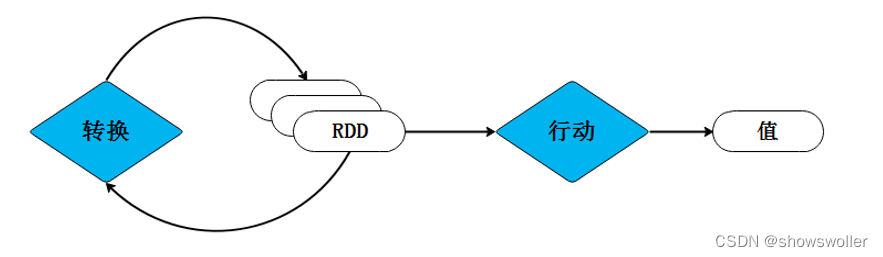
【大数据技术Hadoop+Spark】MapReduce之单词计数和倒排索引实战(附源码和数据集 超详细)
源码和数据集请点赞关注收藏后评论区留言私信~~~一、统计单词出现次数单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World。其主要功能是统计一系列文本文件中每个单词出现的次数程序解析首先MapReduce将文件拆分成splits,由于测试用的文件较小,只有二行文字,所以每个文件为一个split,并将文件按行分割形成<key, va....
【大数据技术Hadoop+Spark】HDFS Shell常用命令及HDFS Java API详解及实战(超详细 附源码)
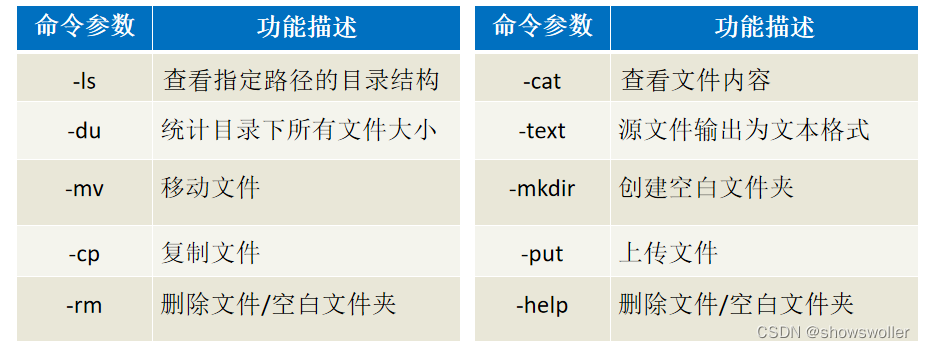
需要源码请点赞关注收藏后评论区留言私信~~~一、HDFS的Shell介绍Shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。文件系统(FS)Shell包含了各种的类Shell的命令,可以直接与Hadoop分布式文件系统以及其他文件系统进行交互。常用命令如下 二、案例-Shel....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxComputespark相关内容
- 云原生大数据计算服务 MaxCompute spark hbase
- spark云原生大数据计算服务 MaxCompute
- 开源spark云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark模型
- 云原生大数据计算服务 MaxCompute spark代码
- 云原生大数据计算服务 MaxCompute spark graphx
- 云原生大数据计算服务 MaxCompute spark redis
- 云原生大数据计算服务 MaxCompute spark学习
- 云原生大数据计算服务 MaxCompute spark scala
- 云原生大数据计算服务 MaxCompute spark计算
- 云原生大数据计算服务 MaxCompute spark案例
- 云原生大数据计算服务 MaxCompute spark集群文件
- 云原生大数据计算服务 MaxCompute spark dstream
- 云原生大数据计算服务 MaxCompute spark优缺点
- 云原生大数据计算服务 MaxCompute spark集群
- 云原生大数据计算服务 MaxCompute spark集群scala
- 云原生大数据计算服务 MaxCompute spark自定义
- 云原生大数据计算服务 MaxCompute spark streaming dstream
- 云原生大数据计算服务 MaxCompute spark数据源
- 云原生大数据计算服务 MaxCompute spark文件
- 云原生大数据计算服务 MaxCompute spark集群案例
- 云原生大数据计算服务 MaxCompute spark dataset
- 云原生大数据计算服务 MaxCompute spark优化
- 云原生大数据计算服务 MaxCompute spark rdd持久化
- 云原生大数据计算服务 MaxCompute spark容错机制
- 云原生大数据计算服务 MaxCompute spark依赖
- 云原生大数据计算服务 MaxCompute spark wordcount
- 云原生大数据计算服务 MaxCompute spark集群模式
- 云原生大数据计算服务 MaxCompute spark编译
- 云原生大数据计算服务 MaxCompute spark hdfs
云原生大数据计算服务 MaxCompute更多spark相关
- 云原生大数据计算服务 MaxCompute spark安装配置
- 云原生大数据计算服务 MaxCompute spark环境配置
- 云原生大数据计算服务 MaxCompute spark环境
- 云原生大数据计算服务 MaxCompute spark部署模式
- dataworks spark节点云原生大数据计算服务 MaxCompute
- spark访问云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark访问
- 云原生大数据计算服务 MaxCompute spark节点
- 云原生大数据计算服务 MaxCompute spark性能
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute spark资源
- 云原生大数据计算服务 MaxCompute spark模式
- 云原生大数据计算服务 MaxCompute框架spark
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute spark运行
- 云原生大数据计算服务 MaxCompute spark实战
- 云原生大数据计算服务 MaxCompute spark sql
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute spark引擎
- 云原生大数据计算服务 MaxCompute hive spark
- 云原生大数据计算服务 MaxCompute学习spark
- 云原生大数据计算服务 MaxCompute spark访问oss
- 云原生大数据计算服务 MaxCompute spark概念
- 云原生大数据计算服务 MaxCompute spark mc
- 云原生大数据计算服务 MaxCompute引擎spark
- 云原生大数据计算服务 MaxCompute spark dataframe
- 数据计算云原生大数据计算服务 MaxCompute spark节点
- spark云原生大数据计算服务 MaxCompute引擎
- 云原生大数据计算服务 MaxCompute spark流程
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute数据预处理
- 云原生大数据计算服务 MaxCompute智能驾驶
- 云原生大数据计算服务 MaxCompute ai
- 云原生大数据计算服务 MaxCompute实时数仓
- 云原生大数据计算服务 MaxCompute构建
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute数仓
- 云原生大数据计算服务 MaxCompute解决方案
- 云原生大数据计算服务 MaxCompute靠谱
- 云原生大数据计算服务 MaxCompute架构
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps

