
通过RootPolicy访问OSS-HDFS
OSS-HDFS服务支持RootPolicy。通过RootPolicy,您可以为OSS-HDFS服务设置自定义前缀。此功能使得Serverless Spark能够在无需修改原有访问hdfs://前缀的任务的情况下,直接操作OSS-HDFS上的数据。
管理自定义配置文件
自定义配置文件功能支持根据特定需求创建个性化配置,灵活控制任务执行环境。支持多种文件格式(如XML和JSON),确保配置的安全性和一致性,并可直接应用于各类任务(如批处理、会话等)。
管理Spark配置模板
Spark配置模板用于定义全局默认配置,支持创建、编辑和管理任务运行所需的参数。通过集中维护 Spark 配置信息,确保任务执行的一致性和灵活性,同时支持动态更新以满足多样化业务需求。
绑定AnalyticDB for Spark计算资源
若您要使用DataWorks进行AnalyticDB for Spark任务的开发、管理,需先将您的云原生数据仓库AnalyticDB for MySQL集群绑定为DataWorks的AnalyticDB for Spark计算资源。绑定完成后,可在DataWorks中使用该计算资源进行数据开发操作。
Serverless Spark计算资源
若您要使用DataWorks进行EMR Serverless Spark任务的开发、管理,需先将您的EMR Serverless Spark工作空间绑定为DataWorks的Serverless Spark计算资源。绑定完成后,可在DataWorks中使用该计算资源进行数据开发操作。
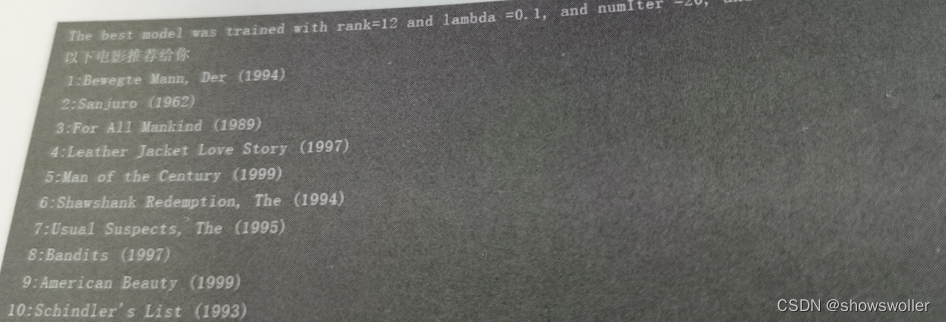
【大数据技术】Spark MLlib机器学习协同过滤电影推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~协同过滤————电影推荐协同过滤是利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。在协同过滤算法中有着两个分支,分别是基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。在电影推荐系统中,通常分为针对用户推荐电影和针对电影推荐用户两种方式。若采用基于用户的推荐模型,则会利用相似用户的评级来计算对某个用户的推....
【大数据技术】Spark MLlib机器学习线性回归、逻辑回归预测胃癌是否转移实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~线性回归过工具类MLUtils加载LIBSVM格式样本文件,每一行的第一个是真实值y,有10个特征值x,用1:double,2:double分别标注,即建立需求函数:y=a_1x_1+a_2x_2+a_3x_3+a_4x_4+…+a_10x_10通过样本数据和梯度下降训练模型,找到10个产生比较合理的参数值(a_1到a_10)回归结果如下部分代....

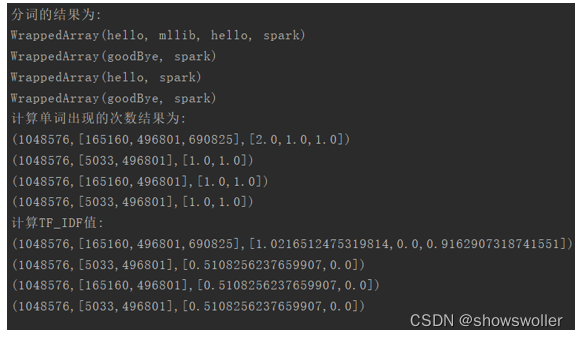
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词出现的次数。它用来度量词对文档的重要程度,TF越大,该词在文档中就越重要。IDF逆向文档频率,是指....
【大数据技术】Spark+Flume+Kafka实现商品实时交易数据统计分析实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~Flume、Kafka区别和侧重点1)Kafka 是一个非常通用的系统,你可以有许多生产者和消费者共享多个主题Topics。相比之下,Flume是一个专用工具被设计为旨在往HDFS,HBase等发送数据。它对HDFS有特殊的优化,并且集成了Hadoop的安全特性。如果数据被多个系统消费的话,使用kafka;如果数据有多个生产者场景,或者有写入Hbase....

【大数据技术Spark】DStream编程操作讲解实战(图文解释 附源码)
DStream编程批处理引擎Spark Core把输入的数据按照一定的时间片(如1s)分成一段一段的数据,每一段数据都会转换成RDD输入到Spark Core中,然后将DStream操作转换为RDD算子的相关操作,即转换操作、窗口操作以及输出操作。RDD算子操作产生的中间结果数据会保存在内存中,也可以将中间的结果数据输出到外部存储系统中进行保存。转换操作1:无状态转换操作无状态转化操作每个批次的....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxComputespark相关内容
- 云原生大数据计算服务 MaxCompute spark hbase
- spark云原生大数据计算服务 MaxCompute
- 开源spark云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark模型
- 云原生大数据计算服务 MaxCompute spark代码
- 云原生大数据计算服务 MaxCompute spark graphx
- 云原生大数据计算服务 MaxCompute spark redis
- 云原生大数据计算服务 MaxCompute spark学习
- 云原生大数据计算服务 MaxCompute spark scala
- 云原生大数据计算服务 MaxCompute spark计算
- 云原生大数据计算服务 MaxCompute spark案例
- 云原生大数据计算服务 MaxCompute spark集群文件
- 云原生大数据计算服务 MaxCompute spark dstream
- 云原生大数据计算服务 MaxCompute spark优缺点
- 云原生大数据计算服务 MaxCompute spark集群
- 云原生大数据计算服务 MaxCompute spark集群scala
- 云原生大数据计算服务 MaxCompute spark自定义
- 云原生大数据计算服务 MaxCompute spark streaming dstream
- 云原生大数据计算服务 MaxCompute spark数据源
- 云原生大数据计算服务 MaxCompute spark文件
- 云原生大数据计算服务 MaxCompute spark集群案例
- 云原生大数据计算服务 MaxCompute spark dataset
- 云原生大数据计算服务 MaxCompute spark优化
- 云原生大数据计算服务 MaxCompute spark rdd持久化
- 云原生大数据计算服务 MaxCompute spark容错机制
- 云原生大数据计算服务 MaxCompute spark依赖
- 云原生大数据计算服务 MaxCompute spark wordcount
- 云原生大数据计算服务 MaxCompute spark集群模式
- 云原生大数据计算服务 MaxCompute spark编译
- 云原生大数据计算服务 MaxCompute spark hdfs
云原生大数据计算服务 MaxCompute更多spark相关
- 云原生大数据计算服务 MaxCompute spark安装配置
- 云原生大数据计算服务 MaxCompute spark环境配置
- 云原生大数据计算服务 MaxCompute spark环境
- 云原生大数据计算服务 MaxCompute spark部署模式
- dataworks spark节点云原生大数据计算服务 MaxCompute
- spark访问云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark访问
- 云原生大数据计算服务 MaxCompute spark节点
- 云原生大数据计算服务 MaxCompute spark性能
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute spark资源
- 云原生大数据计算服务 MaxCompute spark模式
- 云原生大数据计算服务 MaxCompute框架spark
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute spark运行
- 云原生大数据计算服务 MaxCompute spark实战
- 云原生大数据计算服务 MaxCompute spark sql
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute spark引擎
- 云原生大数据计算服务 MaxCompute hive spark
- 云原生大数据计算服务 MaxCompute学习spark
- 云原生大数据计算服务 MaxCompute spark访问oss
- 云原生大数据计算服务 MaxCompute spark概念
- 云原生大数据计算服务 MaxCompute spark mc
- 云原生大数据计算服务 MaxCompute引擎spark
- 云原生大数据计算服务 MaxCompute spark dataframe
- 数据计算云原生大数据计算服务 MaxCompute spark节点
- spark云原生大数据计算服务 MaxCompute引擎
- 云原生大数据计算服务 MaxCompute spark流程
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute数据预处理
- 云原生大数据计算服务 MaxCompute智能驾驶
- 云原生大数据计算服务 MaxCompute ai
- 云原生大数据计算服务 MaxCompute实时数仓
- 云原生大数据计算服务 MaxCompute构建
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute数仓
- 云原生大数据计算服务 MaxCompute解决方案
- 云原生大数据计算服务 MaxCompute靠谱
- 云原生大数据计算服务 MaxCompute架构
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps

