
Hadoop学习笔记:运行wordcount对文件字符串进行统计案例
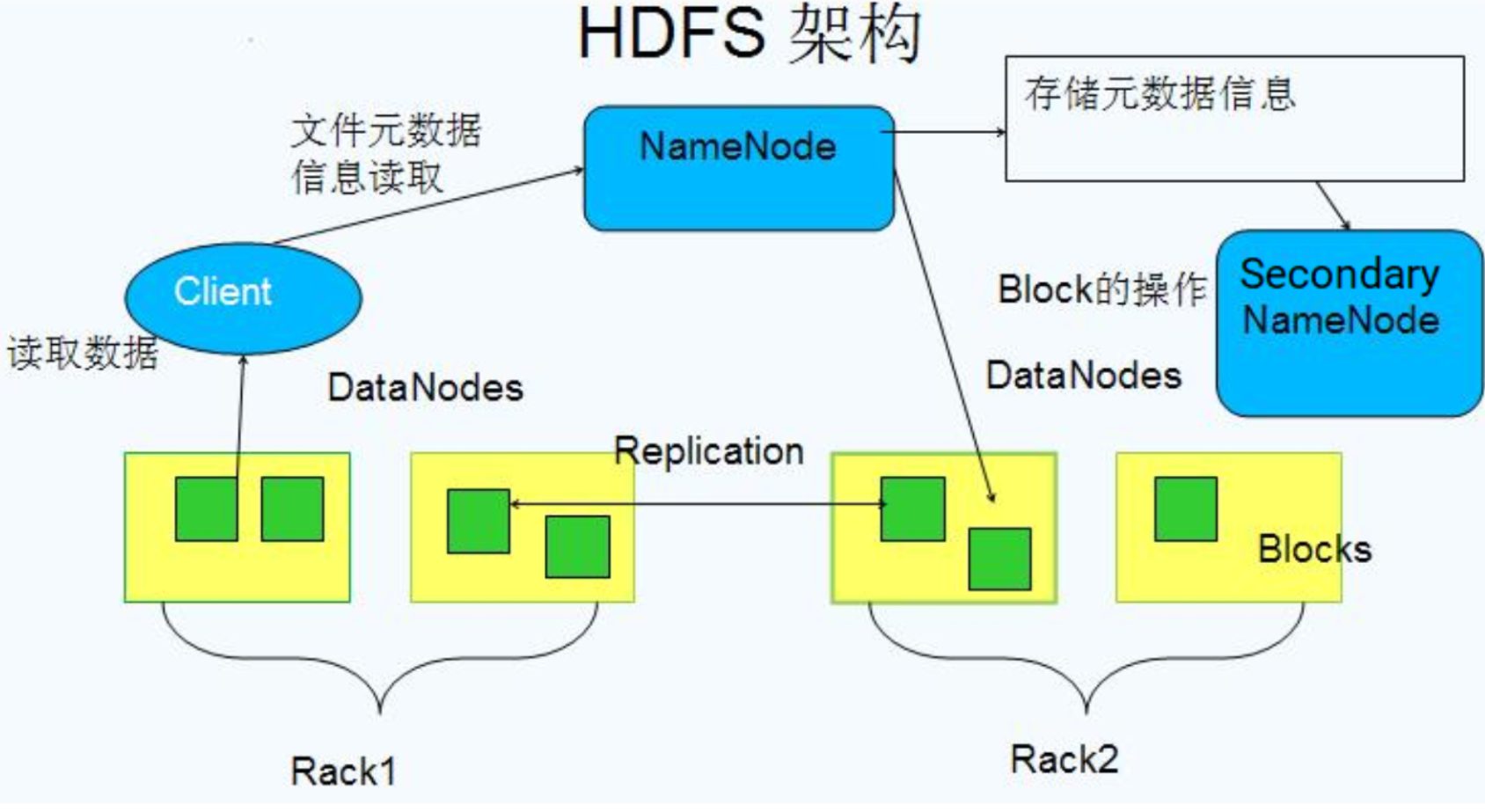
文/朱季谦我最近使用四台Centos虚拟机搭建了一套分布式hadoop环境,简单模拟了线上上的hadoop真实分布式集群,主要用于业余学习大数据相关体系。其中,一台服务器作为NameNode,一台作为Secondary NameNode,剩下两台当做DataNodes节点服务器,类似下面这样一个架构——NameNodeSecondary NameNodeDataNodesmaster1(192.....
如何在EMR的Hadoop集群中运行Spark作业对接DataHub数据_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文介绍如何在E-MapReduce的Hadoop集群,运行Spark作业消费DataHub数据、统计数据个数并打印出来。
Hadoop本地运行模式(Grep案例和WordCount 案例)
前言Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。这里先介绍本地运行模式运行官方Grep案例提供一些文本文件, grep可以从中找到想要匹配的文本1. 在当前用户主(HOME)目录下面创建一个input目录[ytsky@hadoop101 ~]$ mkdir input2.将Hadoop的xml配置文件复制到input[ytsky@hadoop101 ~]$ cp $HAD....

如何解决Dataphin脚本任务运行报错
问题描述Dataphin脚本任务运行报错“Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask“。解决方案上...
三十二、基于Hadoop伪分布式运行Hadoop自带wordcount案例
环境背景:Hadoop伪分布式已经搭建完成Hadoop2.6.0Hadoop伪分布搭建见:Hadoop伪分布式的搭建详情https://blog.csdn.net/m0_54925305/article/details/118650350?spm=1001.2014.3001.5502https://blog.csdn.net/m0_54925305/article/details/118650....

在Hadoop系统中运行WordCount案例失败解决方法
报错提示:mapreduce.shuffle set in yarn.nodemanager.aux-services is invalid请在yarn-site.xml中添加<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle&...
好程序员大数据分享Hadoop2.X的环境配置与运行官方案例
一、安装之前的准备1.1 修改主机名称进入 Linux 系统查看本机的主机名。通过 hostname 命令查看。[root@localhost ~]# hostnamelocalhost.localdomain如果此时需要修改主机名则可以按照如下的方式进行修改范例一:临时修改主机名称为Hadoop01 hostname hadoop01 重启之后失效范例二:永久修改主机名称为Hadoop01vi....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop运行相关内容
- flink cdc hadoop运行
- hadoop运行报错
- hadoop运行job
- 运行hadoop程序
- 运行hadoop统计程序
- hadoop打包运行
- hadoop运行wordcount
- hadoop运行原理
- flink hadoop运行
- hadoop运行wordcount案例
- hadoop运行程序
- hadoop wordcount运行
- hadoop运行解决方法
- hadoop运行实例
- hadoop伪分布运行wordcount
- hadoop运行wordcount程序
- 运行wordcount hadoop
- hadoop wordcount打包运行
- hadoop运行代码
- hadoop组件运行
- 运行hadoop任务
- hadoop分布式运行
- hadoop运行服务
- hadoop reduce运行
- eclipse运行hadoop
- hadoop入门运行
hadoop您可能感兴趣
- hadoop开发环境
- hadoop hbase
- hadoop集群
- hadoop数据处理
- hadoop数据分析
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop技术
- hadoop大数据
- hadoop hdfs
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop分布式
- hadoop数据
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop节点
- hadoop搭建
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作
- hadoop apache