
Paraformer实时语音识别WebSocket API
本文介绍如何通过WebSocket连接访问实时语音识别服务。DashScope SDK目前仅支持Java和Python。若想使用其他编程语言开发Paraformer实时语音识别应用程序,可以通过WebSocket连接与服务进行通信。WebSocket是一种支持全双工通信的网络协议。客户端和服务器通过...
Gummy实时语音识别、翻译WebSocket API
本文介绍如何通过WebSocket连接访问Gummy实时语音识别、翻译服务。DashScope SDK目前仅支持Java和Python。若想使用其他编程语言开发Gummy实时语音识别、翻译应用程序,可以通过WebSocket连接与服务进行通信。WebSocket是一种支持全双工通信的网络协议。客户端...
语音识别(ASR)系列之四:基于Attention的模型
语音识别系列前三篇分别介绍了基本原理、混合模型、端到端模型中的CTC模型和Transducer模型。此篇是系列最后一篇,讲讲基于Attention机制(注意力机制)的端到端模型。\复习AttentionAttention机制毫不夸张地说是近几年机器学习中的大热门,热门的原因确实是因为它在各种场景中能提高模型的准确率。Attention本身的机制和结构不是本篇文章的重点,网上介绍的文章很多,我公众....
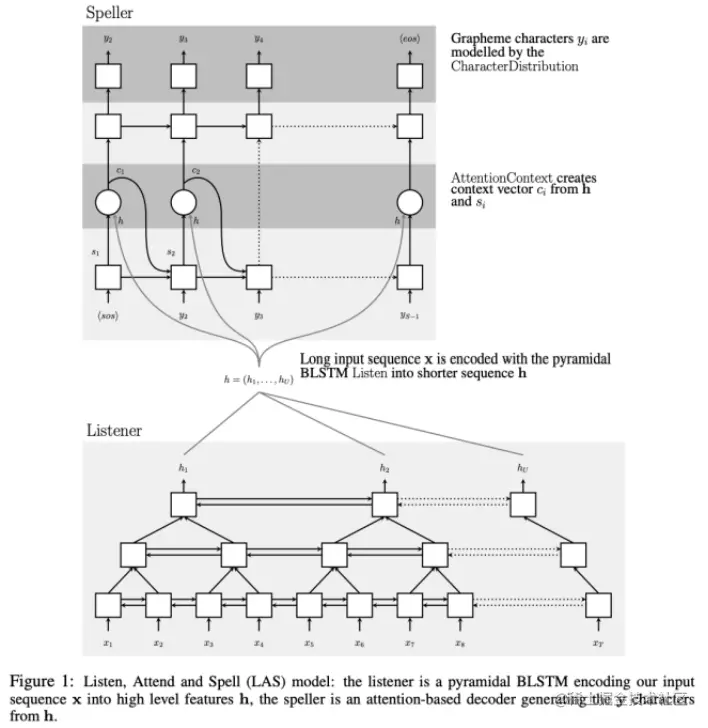
语音识别(ASR)系列之三:CTC、RNN-T模型
上一篇系列之二介绍了早期的混合模型,底层使用GMM或者DNN计算帧对应的音素概率,上层使用HMM寻找最优的音素序列,得到最终的文字序列。该模型的缺点:需要对帧级别打标签、建模,这对语音数据来说工作量巨大,并且标签不一定准确,特别是两个音的边界部分;两个或者多个模型混合增加了模型复杂度,使用不太方便。\\于是后来新的模型思路转向从语音直接预测文字,即端到端模型。今天我们来看看具有里程碑意义的CTC....

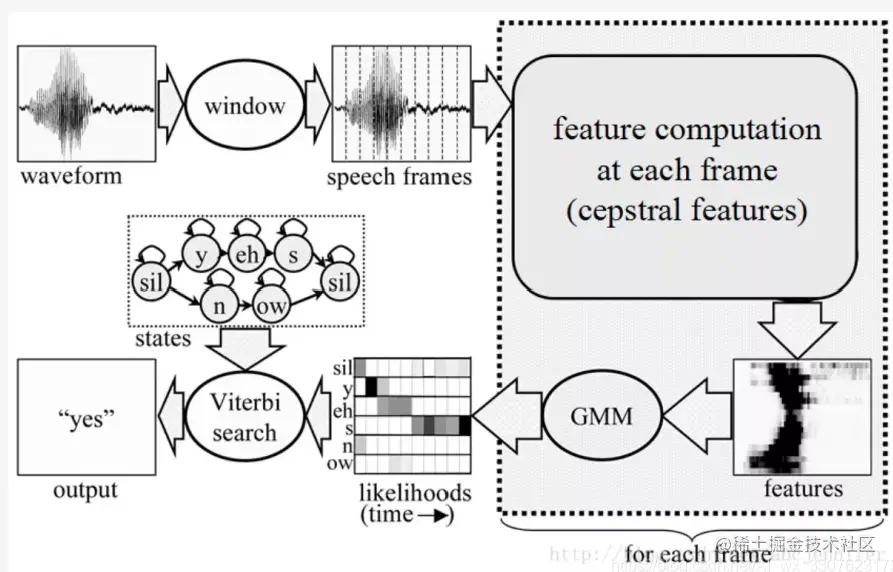
语音识别(ASR)系列之二:混合模型
上篇系列之一从总体上讲了ASR的原理、评估方法、模型发展,这一篇开始介绍称霸ASR三十年的混合模型(Hybrid Model),特别是GMM/HMM模型。由于GMM和HMM模型本身已经是很大的一块内容,我假设读者已经了解其基本原理。网络异常,图片无法展示|基本概念在讲具体模型之前,先介绍一些需要了解的基本概念。对语音进行处理,一般会先进行分帧和特征提取,例如MFCC、FBank,然后把这些特征转....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
智能语音交互模型相关内容
- 开源智能语音交互模型
- 工业级智能语音交互模型
- 开源工业级智能语音交互模型
- 模型智能语音交互
- modelscope-funasr paraformer智能语音交互模型
- paraformer智能语音交互模型
- 训练智能语音交互模型
- 智能语音交互模型文本
- 阿里云智能语音交互模型
- 智能语音交互服务模型
- 智能语音交互模型应用
- 智能语音交互离线模型
- 智能语音交互模型微调
- 智能语音交互模型时间戳
- 端到端智能语音交互模型
- 智能语音交互模型优势
- paraformer智能语音交互声学模型
- 智能语音交互智能语音交互模型
- modelscope-funasr模型流式智能语音交互
- modelscope-funasr模型智能语音交互
- modelscope-funasr paraformer角色智能语音交互模型
- 工业智能语音交互模型
- 智能语音交互模型运行
- 智能语音交互模型方案
- interspeech智能语音交互模型
- paraformer端到端智能语音交互模型
智能语音交互您可能感兴趣
- 智能语音交互文件
- 智能语音交互语音
- 智能语音交互文档
- 智能语音交互大模型
- 智能语音交互whisper
- 智能语音交互funasr
- 智能语音交互asr
- 智能语音交互tts
- 智能语音交互报错
- 智能语音交互协议
- 智能语音交互阿里
- 智能语音交互阿里云
- 智能语音交互识别
- 智能语音交互modelscope-funasr
- 智能语音交互服务
- 智能语音交互技术
- 智能语音交互sdk
- 智能语音交互语音合成
- 智能语音交互功能
- 智能语音交互应用
- 智能语音交互paraformer
- 智能语音交互接口
- 智能语音交互文本
- 智能语音交互语音识别
- 智能语音交互产品
- 智能语音交互智能语音交互
- 智能语音交互离线
- 智能语音交互音频
- 智能语音交互系统
- 智能语音交互python


