
人工智能LLM模型:奖励模型的训练、PPO 强化学习的训练、RLHF
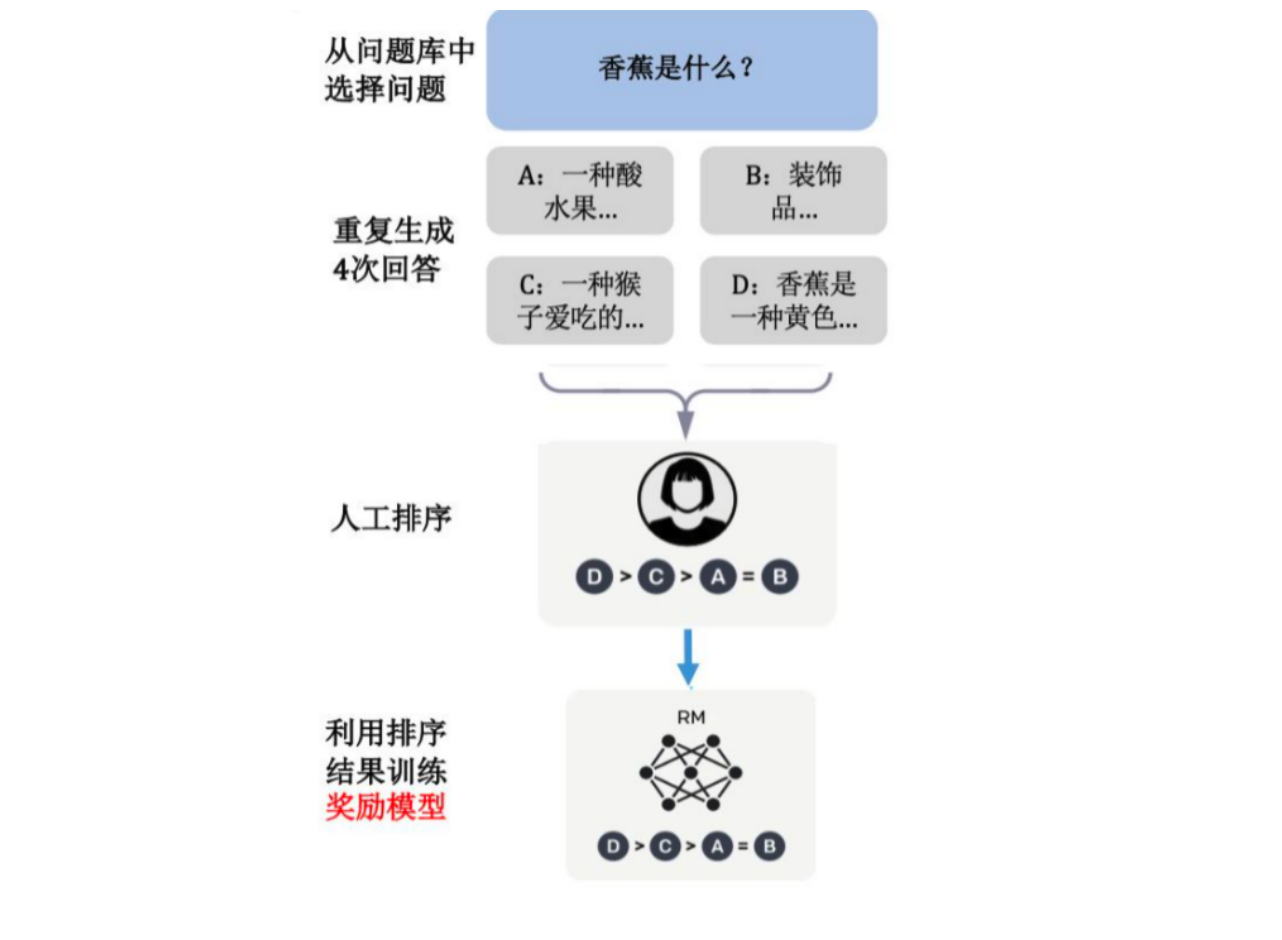
人工智能LLM模型:奖励模型的训练、PPO 强化学习的训练、RLHF 1.奖励模型的训练 1.1大语言模型中奖励模型的概念 在大语言模型完成 SFT 监督微调后,下一阶段是构建一个奖励模型来对问答对作出得分评价。奖励模型源于强化学习中的奖励函数,能对当前的状态刻画一个分数,来说明这个状态产生的价值有多少。在大语言模型微调中的奖励模型是对输入的问题和答案计算出一个分数。输入的答案与问题匹配度...
[人工智能]得人工智能者得天下?百度200万美元奖励不到20人的团队
8月8日下午,李彦宏把分布在全国各地的三四万人中的一万人,召集在百度大厦东广场,举行了个超级大的Summer Party,据说是因为从今年开始,这就是百度的年会了(所以才会有百度高管一起小苹果这样一年一度的欢乐节目)。这次场子里除了近万人的夏日狂欢,还有李彦宏亲自颁发超级巨奖,也就是所谓2014年度的“百度最高奖”,今年奖金达到600万美元,是过去三年的总和,四年累计共发出1200万美元,说在中....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。