
Kafka 时间轮算法
@[TOC] 前言 Kafka中存在大量的延时操作。 发送消息-超时+重试机制的延时。 ACKS 确认机制的延时。 Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer) JDK的Timer和DelayQueue插入和删除操作的平均时间复杂度为O(log(n)),并不能满足...
【Kafka从入门到成神系列 三】Kafka 生产者消息分区及压缩算法
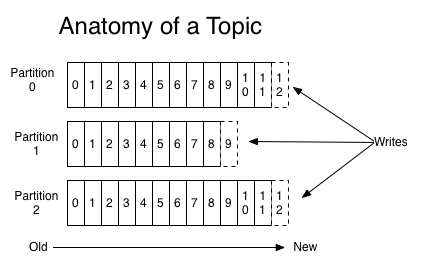
、生产者消息分区机制当我们在使用 Kafka 时,我们肯定希望将数据均匀的分配到所有服务器上。这样,我们的负载均衡就变的及其完美。1. 分区原因简单来说,Kafka 的消息组织方式结构:主题 - 分区 - 副本 - 消息。一条消息,只能保存到一个分区内,不会在多个分区保存多份。简单想想,为什么我们的 Kafka 已经有 Topic 了,还需要做一个分区出来呢?主要的原因在于:实现系统的高伸缩性,....
Kafka的心跳处理机制竟然用到了时间轮算法?
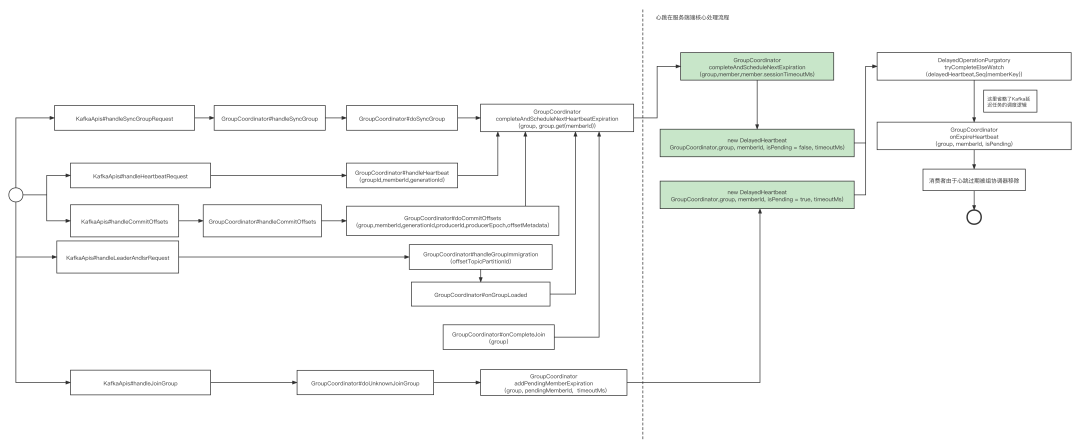
Broker端与客户端的心跳在Kafka中非常的重要,因为一旦在一个心跳过期周期内(默认10s),Broker端的消费组组协调器(GroupCoordinator)会把消费者从消费组中移除,从而触发重平衡。在2.4.x以下其版本中,消费组一旦进入重平衡状态,该消费组内所有消费者全部暂停消费,直到重平衡完成。本文将来探讨Kafka的心跳机制的具体实现。本文的组织结构如下:源码解读Kafka心跳机制....
原创Kafka学习笔记,java空间换时间算法
1、为什么要使用消息队列?分析:一个用消息队列的人,不知道为啥用,有点尴尬。没有复习这点,很容易被问蒙,然后就开始胡扯了。回答:这个问题,咱只答三个最主要的应用场景(不可否认还有其他的,但是只答三个主要的),即以下六个字:解耦、异步、削峰(1)解耦传统模式:传统模式的缺点:系统间耦合性太强,如上图所示,系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦....

Kafka竟然也用二分搜索算法查找索引!(下)
改进版二分查找算法显然不是!我前面说过了,大多数操作系统使用页缓存来实现内存映射,而目前几乎所有的操作系统都使用LRU(Least Recently Used)或类似于LRU的机制来管理页缓存。Kafka写入索引文件的方式是在文件末尾追加写入,而几乎所有的索引查询都集中在索引的尾部。这么来看的话,LRU机制是非常适合Kafka的索引访问场景的。但,这里有个问题是,当Kafka在查询索引的时候,原....
Kafka竟然也用二分搜索算法查找索引!(中)
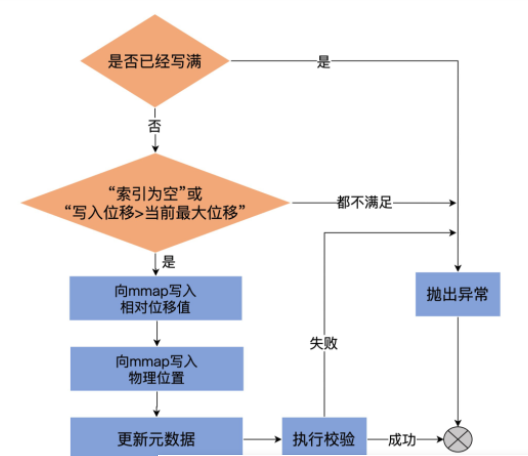
写入索引项下面这段代码是OffsetIndex的append方法,用于向索引文件中写入新索引项。 def append(offset: Long, position: Int): Unit = { inLock(lock) { // 第1步:判断索引文件未写满 require(!isFull, "Attempt to append to a...
Kafka竟然也用二分搜索算法查找索引!(上)
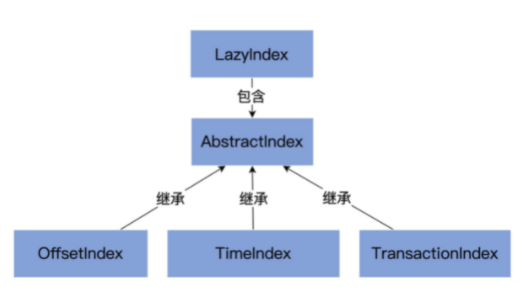
索引应用二分查找算法快速定位查询索引项。难得的是,Kafka的索引组件中应用了二分查找算法,而且社区还针对Kafka自身的特点对其进行了改良。索引类图及源文件组织架构都位于core包的/src/main/scala/kafka/logAbstractIndex.scala定义了最顶层的抽象类,这个类封装了所有索引类型的公共操作。LazyIndex.scala定义了AbstractIndex上的一....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

智能搜索推荐
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。
+关注