
使用DLF
本文介绍了如何在EMR Serverless Spark中开发并运行一个基于数据湖构建(DLF)的Paimon表写入任务。通过上传测试文件、创建任务并运行,最终可以通过日志探查或控制台查看结果,验证数据写入和查询的正确性。
使用Delta Lake
Delta Lake是一个开源存储框架,旨在数据湖之上构建LakeHouse架构。Delta Lake提供了ACID事务支持、可扩展的元数据处理功能,并能够在现有的数据湖(如OSS、Amazon S3和HDFS)上整合流处理与批处理。此外,Delta Lake还支持多种引擎,如Spark、PrestoDB和Flink,以及多种编程语言的API,包括Scala、Java、Rust和Python,以便...
配置Livy Gateway以启用Ranger鉴权,实现细粒度访问控制和安全策略管理。
Apache Ranger提供了集中式的权限管理框架。通过与Spark结合使用的Ranger Plugin,可以对Spark SQL访问数据库、表和列等进行细粒度的权限控制,从而增强数据访问的安全性。Livy Gateway支持配置Ranger Plugin来启用数据访问的权限控制。
PAI-DSW连接EMR Serverless Spark提交PySpark任务
阿里云人工智能PAI-DSW提供了云端AI开发IDE或开发机,内置多种开发环境,可以快速开始模型开发。您可以在DSW中,利用Serverless Spark提供的Livy API,远程连接Serverless Spark,并将PySpark任务提交至服务端进行执行。
执行角色
EMR Serverless Spark工作空间中的任务在调用其他阿里云服务(如OSS、DLF)时,将通过执行角色进行权限验证。在创建工作空间时,您既可以使用默认执行角色,也可以使用自定义的角色。
【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件夹scala,界面如下:6) 将文件夹scala设置成Source Root,界面如下:7) 新建....
【大数据技术Hadoop+Spark】Spark SQL、DataFrame、Dataset的讲解及操作演示(图文解释)
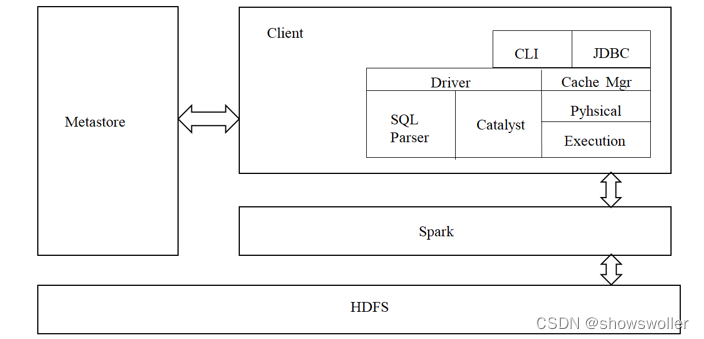
一、Spark SQL简介park SQL是spark的一个模块,主要用于进行结构化数据的SQL查询引擎,开发人员能够通过使用SQL语句,实现对结构化数据的处理,开发人员可以不了解Scala语言和Spark常用API,通过spark SQL,可以使用Spark框架提供的强大的数据分析能力。spark SQL前身为Shark。Shark是Spark上的数据仓库,最初设计成与Hive兼容,但是该项目....
大数据Spark DataFrame/DataSet常用操作2
3 多表操作Join3.1 数据准备先构建两个DataFramescala> val df1 = spark.createDataset(Seq(("a", 1,2), ("b",2,3) )).toDF("k1","k2","k3") df1: org.apache.spark.sql.DataFrame = [k1: string, k2: int ... 1 more field].....
大数据Spark DataFrame/DataSet常用操作1
1 一般操作:查找和过滤1.1 读取数据源1.1.1读取json使用spark.read。注意:路径默认是从HDFS,如果要读取本机文件,需要加前缀file://,如下scala> val people = spark.read.format("json").load("file:///opt/software/data/people.json") people: org.apache.s....

大数据Spark DataFrame/DataSet常用操作4
3.2.2 其他join类型,只需把inner改成你需要的类型即可scala> df1.join(df2,Seq("k1"),"left").show +---+---+---+---+---+ | k1| k2| k3| k2| k4| +---+---+---+---+---+ | a| 1| 2| 2| 2| | b| 2| 3| 2| 1| | b| 2| ...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxComputespark相关内容
- 云原生大数据计算服务 MaxCompute spark hbase
- spark云原生大数据计算服务 MaxCompute
- 开源spark云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark模型
- 云原生大数据计算服务 MaxCompute spark代码
- 云原生大数据计算服务 MaxCompute spark graphx
- 云原生大数据计算服务 MaxCompute spark redis
- 云原生大数据计算服务 MaxCompute spark学习
- 云原生大数据计算服务 MaxCompute spark scala
- 云原生大数据计算服务 MaxCompute spark计算
- 云原生大数据计算服务 MaxCompute spark案例
- 云原生大数据计算服务 MaxCompute spark集群文件
- 云原生大数据计算服务 MaxCompute spark dstream
- 云原生大数据计算服务 MaxCompute spark优缺点
- 云原生大数据计算服务 MaxCompute spark集群
- 云原生大数据计算服务 MaxCompute spark集群scala
- 云原生大数据计算服务 MaxCompute spark自定义
- 云原生大数据计算服务 MaxCompute spark streaming dstream
- 云原生大数据计算服务 MaxCompute spark数据源
- 云原生大数据计算服务 MaxCompute spark文件
- 云原生大数据计算服务 MaxCompute spark集群案例
- 云原生大数据计算服务 MaxCompute spark dataset
- 云原生大数据计算服务 MaxCompute spark优化
- 云原生大数据计算服务 MaxCompute spark rdd持久化
- 云原生大数据计算服务 MaxCompute spark容错机制
- 云原生大数据计算服务 MaxCompute spark依赖
- 云原生大数据计算服务 MaxCompute spark wordcount
- 云原生大数据计算服务 MaxCompute spark集群模式
- 云原生大数据计算服务 MaxCompute spark编译
- 云原生大数据计算服务 MaxCompute spark hdfs
云原生大数据计算服务 MaxCompute更多spark相关
- 云原生大数据计算服务 MaxCompute spark安装配置
- 云原生大数据计算服务 MaxCompute spark环境配置
- 云原生大数据计算服务 MaxCompute spark环境
- 云原生大数据计算服务 MaxCompute spark部署模式
- dataworks spark节点云原生大数据计算服务 MaxCompute
- spark访问云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark访问
- 云原生大数据计算服务 MaxCompute spark节点
- 云原生大数据计算服务 MaxCompute spark性能
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute spark资源
- 云原生大数据计算服务 MaxCompute spark模式
- 云原生大数据计算服务 MaxCompute框架spark
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute spark运行
- 云原生大数据计算服务 MaxCompute spark实战
- 云原生大数据计算服务 MaxCompute spark sql
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute spark引擎
- 云原生大数据计算服务 MaxCompute hive spark
- 云原生大数据计算服务 MaxCompute学习spark
- 云原生大数据计算服务 MaxCompute spark访问oss
- 云原生大数据计算服务 MaxCompute spark概念
- 云原生大数据计算服务 MaxCompute spark mc
- 云原生大数据计算服务 MaxCompute spark实战源码
- 云原生大数据计算服务 MaxCompute引擎spark
- 数据计算云原生大数据计算服务 MaxCompute spark节点
- spark云原生大数据计算服务 MaxCompute引擎
- 云原生大数据计算服务 MaxCompute spark流程
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute交通
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute流量
- 云原生大数据计算服务 MaxCompute聚簇
- 云原生大数据计算服务 MaxCompute pb
- 云原生大数据计算服务 MaxCompute shuffle
- 云原生大数据计算服务 MaxCompute cu
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute功能
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute分区
- 云原生大数据计算服务 MaxCompute项目

