
ML之XGBoost:利用XGBoost算法对波士顿数据集回归预测(模型调参【2种方法,ShuffleSplit+GridSearchCV、TimeSeriesSplitGSCV】、模型评估)
目录利用XGBoost算法对波士顿数据集回归预测T1、ShuffleSplit+GSCV模型调参T2、TimeSeriesSplit=GSCV模型调参 相关文章ML之XGBoost:利用XGBoost算法对波士顿数据集回归预测(模型调参【2种方法,ShuffleSplit+GridSearchCV、TimeSeriesSplitGSCV】、模型评估)ML之XGBoost:利....
ML之XGBoost:利用XGBoost算法对波士顿数据集回归预测(模型调参【2种方法,ShuffleSplit+GridSearchCV、TimeSeriesSplitGSCV】、模型评估)
T2、TimeSeriesSplit=GSCV模型调参输出XGBR_GSCV模型最佳得分、最优参数:0.8772,{'learning_rate': 0.15, 'max_depth': 3, 'n_estimators': 200}XGBR_TimeS_GSCV time: 365.73213645175XGBoost Score value: 0.8392863414585984XGBoos....
ML之XGBoost:利用XGBoost算法对波士顿数据集回归预测(模型调参【2种方法,ShuffleSplit+GridSearchCV、TimeSeriesSplitGSCV】、模型评估)
利用XGBoost算法对波士顿数据集回归预测T1、ShuffleSplit+GSCV模型调参输出XGBR_GSCV模型最佳得分、最优参数:0.8630,{'learning_rate': 0.12, 'max_depth': 3, 'n_estimators': 200}XGBR_Shuffle_GSCV time: 256.7015066994206XGBoost Score value: 0....
ML之xgboost&GBM:基于xgboost&GBM算法对HiggsBoson数据集(Kaggle竞赛)训练(两模型性能PK)实现二分类预测
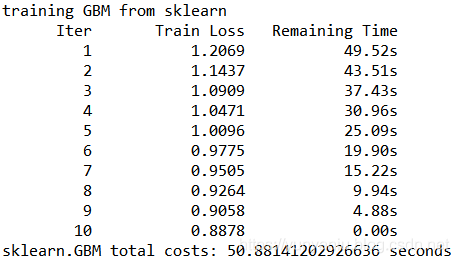
输出结果 设计思路 核心代码finish loading from csv weight statistics: wpos=1522.37, wneg=904200, ratio=593.94loading data end, start to boost treestraining GBM from sklearn Iter &...
ML之xgboost:基于xgboost(5f-CrVa)算法对HiggsBoson数据集(Kaggle竞赛)训练实现二分类预测(基于训练好的模型进行新数据预测)
输出结果 设计思路 核心代码xgmat = xgb.DMatrix( data, missing = -999.0 ) bst = xgb.Booster({'nthread':8}, model_file = modelfile)res = [ ( int(idx[i]), ypred[i] ) for i in range(len(ypred)) ....
ML之xgboost:基于xgboost(5f-CrVa)算法对HiggsBoson数据集(Kaggle竞赛)训练(模型保存+可视化)实现二分类预测
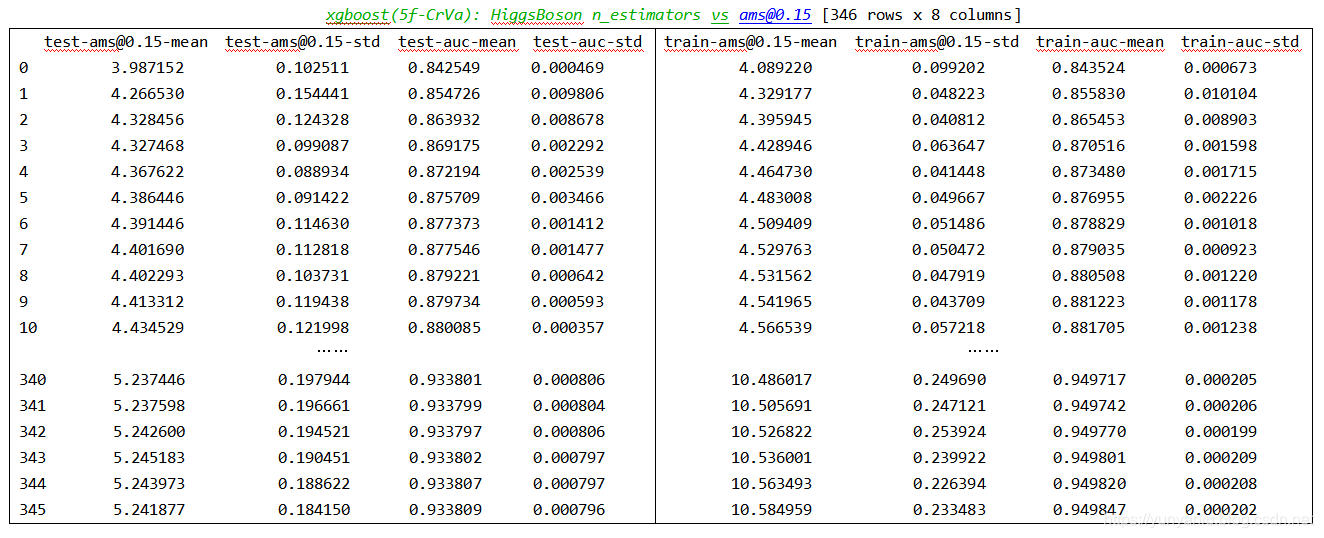
输出结果 设计思路 核心代码num_round = 1000 n_estimators = cvresult.shape[0] print ('running cross validation, w....
ML之xgboost:利用xgboost算法(自带,特征重要性可视化+且作为阈值训练模型)训练mushroom蘑菇数据集(22+1,6513+1611)来预测蘑菇是否毒性(二分类预测)
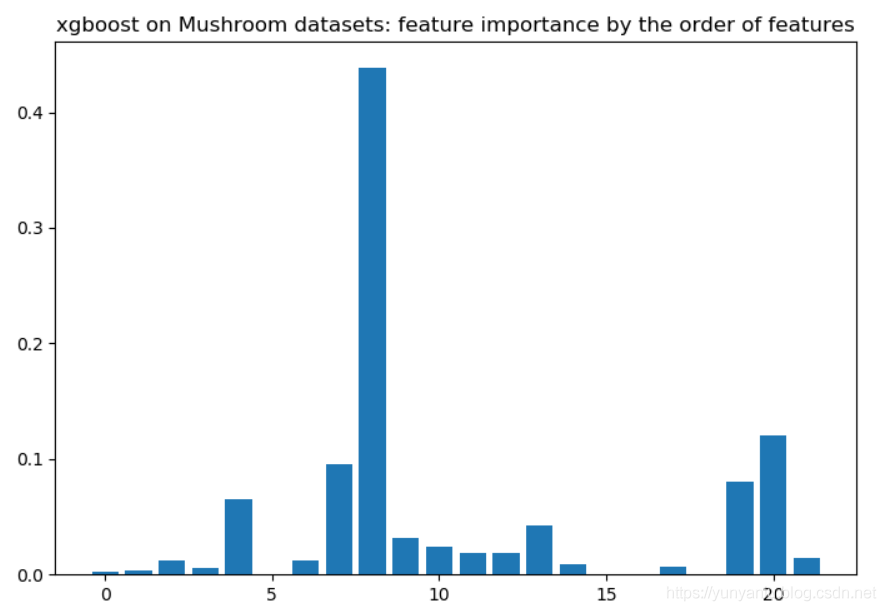
输出结果设计思路核心代码print('XGB_model.feature_importances_:','\n', XGB_model.feature_importances_)from matplotlib import pyplotpyplot.bar(range(len(XGB_model.feature_importances_)), XGB_model.feature_importan....
ML之xgboost:利用xgboost算法(sklearn+GridSearchCV)训练mushroom蘑菇数据集(22+1,6513+1611)来预测蘑菇是否毒性(二分类预测)
输出结果 设计思路 核心代码from sklearn.grid_search import GridSearchCVparam_test = { 'n_estimators': range(1, 51, 1)}clf = GridSearchCV(estimator = bst, param_grid = param_test, cv=5)clf.fit(X_train, y....
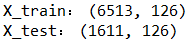
ML之xgboost:利用xgboost算法(sklearn+7CrVa)训练mushroom蘑菇数据集(22+1,6513+1611)来预测蘑菇是否毒性(二分类预测)
输出结果设计思路核心代码kfold = StratifiedKFold(n_splits=10, random_state=7) #fit_params = {'eval_me....
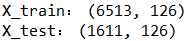
ML之xgboost:利用xgboost算法(sklearn+3Split)训练mushroom蘑菇数据集(22+1,6513+1611)来预测蘑菇是否毒性(二分类预测)
输出结果设计思路核心代码seed = 7test_size = 0.33X_train_part, X_validate, y_train_part, y_validate = train_test_split(X_train, y_train, &n...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法数据集相关内容
- 算法鸢尾花数据集
- svm算法数据集
- k-means算法数据集
- 聚类算法数据集
- 算法数据集源码
- 数据集算法
- 协同过滤算法数据集
- 目标检测算法数据集
- svm数据集算法
- 决策树算法数据集
- 算法iris数据集源码
- 算法决策树数据集
- knn算法数据集
- 数据挖掘算法数据集
- 数据挖掘算法数据集源码
- 决策算法数据集
- kmeans算法数据集
- 线性回归算法数据集
- 算法数据集训练
- 算法数据集验证
- 算法房价数据集
- 数据集apriori算法计算复杂度
- unet算法数据集格式
- ml nb算法数据集
- ml lor算法数据集
- lstm算法数据集
- dl算法数据集训练
- tf框架算法数据集
- dl框架算法数据集
- dl数据集算法回归预测
算法更多数据集相关
- ml lor算法数据集分类
- 算法kaggle数据集
- 算法影评数据集情感分析
- tensorflow框架算法数据集
- 算法数据集回归预测
- 自定义算法数据集
- 数据集算法回归预测
- dl数据集算法
- ml数据集算法
- ml lor数据集算法
- cnn算法数据集
- 算法mnist数据集
- 算法boston数据集
- 算法数据集二分类
- ml rf算法数据集
- 算法泰坦尼克数据集
- ml数据集knn算法
- ml回归预测算法数据集
- dl算法mnist数据集
- 算法数据集评估
- ml算法波士顿数据集
- ml算法boston房价数据集
- ml算法数据集回归预测
- 算法平台数据集
- rf算法泰坦尼克号数据集分类
- nb数据集朴素贝叶斯算法
- 算法数据集kaggle
- iris莺尾花数据集算法
- 算法mnist数据集训练
- 数据集pca算法

智能引擎技术
AI Online Serving,阿里巴巴集团搜推广算法与工程技术的大本营,大数据深度学习时代的创新主场。
+关注