
【Spark MLlib】(一)架构解析(包含分类、回归、聚类和协同过滤)
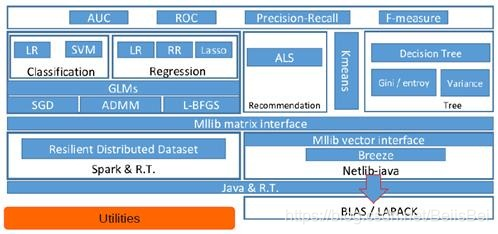
文章目录一、前言二、MLlib的底层基础解析三、MLlib的算法库分析四、MLlib的实用程序分析一、前言从以下架构图可以看出MLlib主要包含三个部分:底层基础:包括Spark的运行库、矩阵库和向量库;算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法;实用程序:包括测试数据的生成、外部数据的读入等功能。二、MLlib的底层基础解析底层基础部分主要包括向量接口和矩阵接口,这两种接口都....
Spark MLlib中KMeans聚类算法的解析和应用
本文转自公众号:大数据学习与分享原文链接 聚类算法是机器学习中的一种无监督学习算法,它在数据科学领域应用场景很广泛,比如基于用户购买行为、兴趣等来构建推荐系统。 核心思想可以理解为,在给定的数据集中(数据集中的每个元素有可被观察的n个属性),使用聚类算法将数据集划分为k个子集,并且要求每个子集内部的元素之间的差异度尽可能低,而不同子集元素的差异度尽可能高。简而言之,就是通过聚类算法处理给定的数.....

MLlib 中的聚类和分类
1. 聚类和分类 (1)什么是聚类 聚类( Clustering)指将数据对象分组成为多个类或者簇( Cluster),它的目标是:在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。其实,聚类在 人们日常生活中是一种常见行为,即所谓的“物以类聚,人以群分”,其核心思想在于分组,人们不断地改进聚类模式来学习如何区分各个事物和人。 (2)什么是分类 数据仓库、数据库或者其他信息库中有....
Spark MLlib架构解析(含分类算法、回归算法、聚类算法和协同过滤)
Spark MLlib架构解析 MLlib的底层基础解析 MLlib的算法库分析 分类算法 回归算法 聚类算法 协同过滤 MLlib的实用程序分析 从架构图可以看出MLlib主要包含三个部分: 底层基础:包括Spark的运行库、矩阵库和向量库;...
Spark MLlib聚类KMeans
算法说明 聚类(Cluster analysis)有时也被翻译为簇类,其核心任务是:将一组目标object划分为若干个簇,每个簇之间的object尽可能相似,簇与簇之间的object尽可能相异。聚类算法是机器学习(或者说是数据挖掘更合适)中重要的一部分,除了最为简单的K-Means聚类算法外,比较常见的还有层次法(CURE、CHAMELEON等)、网格算法(STING、WaveCluster....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
人工智能
了解行业+人工智能最先进的技术和实践,参与行业+人工智能实践项目
+关注