
使用Hadoop命令操作OSS/OSS-HDFS
在使用阿里云EMR Serverless Spark的Notebook时,您可以通过Hadoop命令直接访问OSS或OSS-HDFS数据源。本文将详细介绍如何通过Hadoop命令操作OSS/OSS-HDFS。
与自建集群的对比优势
与自建Hadoop集群相比,开源大数据开发平台EMR提供弹性资源管理和自动化运维,降低运维复杂度,通过用户管理、数据加密和权限管理等为数据安全保驾护航,同时EMR集成了丰富的开源组件并打通开源生态与阿里云生态,便于快速搭建大数据处理和分析场景。
基于Hadoop集群支持Delta Lake或Hudi存储机制
Delta Lake和Hudi是数据湖方案中常用的存储机制,为数据湖提供流处理、批处理能力。MaxCompute基于开源的Hadoop集群提供了支持Delta或Hudi存储机制的湖仓一体架构。您可以通过MaxCompute查询到实时数据,即时洞察业务数据变化。
迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
【大数据技术Hadoop+Spark】Spark RDD设计、运行原理、运行流程、容错机制讲解(图文解释)
一、RDD的概念RDD(Resilient Distributed Dataset),即弹性分布式数据集,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并且还能控制数据的分区。不同RDD之间可以通过转换操作形成依赖关系实现管道化,从而避免了中间结果的I/O操作,提高数据处理的速度和性能。一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成....
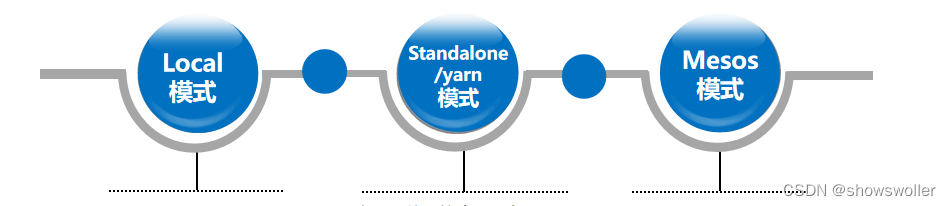
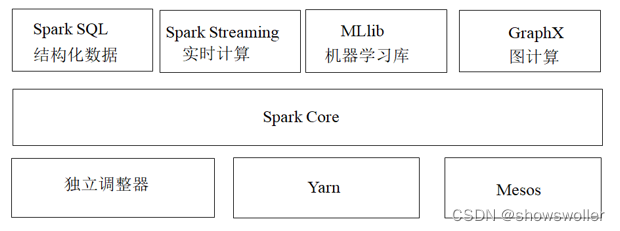
【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如....
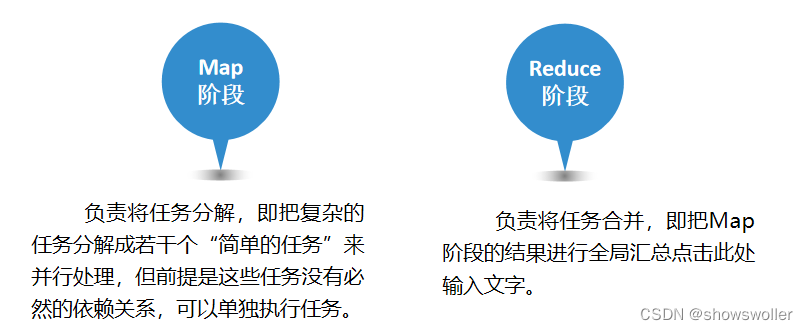
【大数据技术Hadoop+Spark】MapReduce概要、思想、编程模型组件、工作原理详解(超详细)
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。一、MapReduce核心思想MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结....
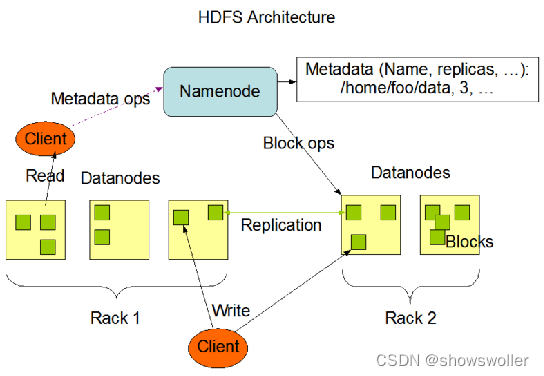
【大数据技术Hadoop+Spark】HDFS概念、架构、原理、优缺点讲解(超详细必看)
一、相关基本概念文件系统。文件系统是操作系统提供的用于解决“如何在磁盘上组织文件”的一系列方法和数据结构。分布式文件系统。分布式文件系统是指利用多台计算机协同作用解决单台计算机所不能解决的存储问题的文件系统。如单机负载高、数据不安全等问题。HDFS。英文全称为Hadoop Distributed File System,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,它是基于流....
【大数据处理框架】Hadoop大数据处理框架,包括其底层原理、架构、编程模型、生态圈
Hadoop是一个开源的大数据处理框架,它包含了底层的分布式文件系统和分布式计算资源管理系统,以及高级的数据处理编程接口。底层原理Hadoop是一个开源的大数据处理框架,它的底层原理是基于分布式计算和存储的。首先,我们来了解一下HDFS。HDFS是Hadoop的核心组件之一,它是一个分布式文件系统,将文件分成多个数据块,并存储在集群中的不同节点上,每个数据块的默认大小为128MB。为了保证数据的....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop大数据相关内容
- hadoop spark大数据
- hadoop spark大数据协同
- 大数据hadoop环境
- 大数据学习hadoop
- 大数据hadoop
- 大数据hadoop分析
- 大数据spark模式hadoop
- 大数据模式hadoop
- 大数据部署hadoop
- 大数据hadoop mapreduce
- 大数据hadoop yarn
- 大数据hadoop节点
- 大数据hadoop笔记
- 大数据hadoop分发
- 大数据hadoop配置
- 大数据环境搭建hadoop
- 大数据组件hadoop
- hadoop入门大数据
- hadoop构建大数据分析
- hadoop概述大数据
- hadoop构建大数据
- hadoop系统大数据
- 大数据hadoop spark
- 大数据maxcompute hadoop
- 阿里巴巴大数据hadoop系统
- 大数据hadoop系统
- 大数据hadoop安装
- 大数据hadoop集成
- 大数据java hadoop
- hadoop大数据工具
hadoop更多大数据相关
- 大数据技术hadoop
- 大数据hadoop集群搭建
- hadoop系统大数据技术
- hadoop大数据入门
- 大数据hadoop伪分布
- 大数据hadoop安装教程
- 大数据hadoop教程
- 大数据hadoop入门
- 大数据hadoop简介
- 大数据hadoop mapreduce编程
- 大数据开发hadoop
- 大数据hadoop编程
- 大数据面试hadoop
- 大数据hadoop分布式
- 大数据实战hadoop
- 大数据hadoop开发
- 大数据实践hadoop
- 大数据hadoop应用
- 大数据面试题百日hadoop
- 大数据开发hadoop安装
- 大数据hadoop hive
- hadoop分布式大数据
- 大数据hadoop部署
- 大数据hadoop hbase
- 大数据hadoop运行
- 大数据hadoop技术
- 大数据框架hadoop
- 大数据环境hadoop
- 大数据hadoop命令
- 大数据原理hadoop
hadoop您可能感兴趣
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop技术
- hadoop集群管理
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop分布式
- hadoop集群
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作
- hadoop apache