
日志相似度聚类、词频聚类和模板匹配算法说明
日志服务异常智能分析应用提供文本分析功能,用于对日志中的文本日志进行智能化、自动化的分析,提供全局的统计分析结果。文本分析功能通过日志模板发现和日志模板匹配两个子任务,实现对于日志数据的监控和统计。您可以根据待分析的日志数据的特点,选择不同的任务和算法。
密度聚类DBSCAN、主成分分析PCA算法讲解及实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~一、基于密度的聚类基于密度的聚类算法的主要思想是:只要邻近区域的密度(对象或数据点的数目)超过某个阀值,就把它加到与之相近的聚类中。也就是说,对给定类中的每个数据点,在一个给定范围的区域中必须至少包含某个数目的点基于密度的聚类算法代表算法有:DBSCAN算法、OPTICS算法及DENCLUE算法等DBSCAN算法涉及2个参数5个定义1)2个参数: Ep....

聚类kmeans和DBSCAN算法的简单实现
在无监督学习中,我们首先就会接触到kmeans算法,因为既简单,又实用,而且速度也很快。所以今天在这里写一个非常简单的kmeans算法,以帮助我们更快的领悟算法的思想,以及它的变种。一下是其实现步骤1.确定聚类数,数据分为多少类。2.随机初始化每一类的中心点。3.计算每一个样本点到每一类中心点的距离,并分配给距离它最小的那个中心点。4.更新中心点,新的中心点为属于它所有点的平均值。5.重复3,4....
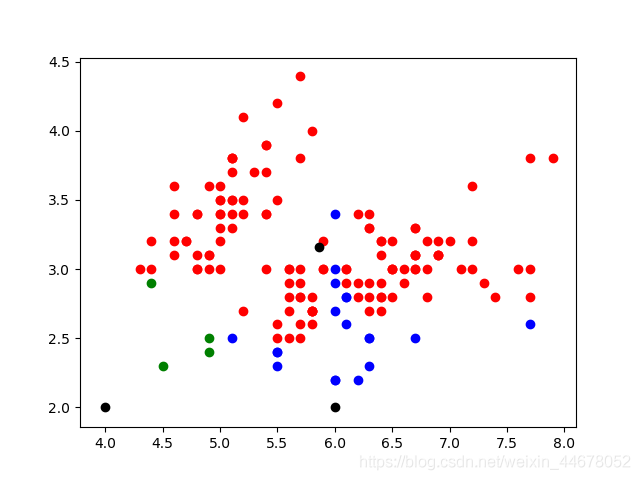
使用ST_ClusterKMeans返回基于二维K均值算法生成的聚类结果数量(PostgreSQL引擎)
返回每个Geometry对象基于二维K均值算法生成的聚类结果数量。
基于密度的聚类之Dbscan算法
一.算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类(笔者认为是因为他不是基于距离的,基于距离的发现的是球状簇)。 ....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

智能引擎技术
AI Online Serving,阿里巴巴集团搜推广算法与工程技术的大本营,大数据深度学习时代的创新主场。
+关注