
备份中心工作原理及使用场景
容器服务ACK备份中心为无状态或有状态应用的备份、恢复与迁移提供了一站式的解决方案,特别是对混合云、多集群的有状态应用提供了数据容灾和应用迁移能力。例如,集群内应用和数据的定时备份、统一恢复,以及跨可用区、跨地域的迁移。本文介绍备份中心的工作原理、计费说明及使用场景。
PolarDB-X中自增列的相关概念和原理_云原生数据库PolarDB分布式版_云原生数据库 PolarDB(PolarDB)
本文将为您介绍PolarDB-X中自增列的相关概念和原理。
服务网格的工作原理是什么
培训视频观看以下视频,快速了解服务网格工作原理:MOSN 形态现状目前 MOSN 属于数据面的产品,以 Sidecar 的模式和应用部署在同一个 Pod 或者在虚拟机中,属于独立进程。MOSN 最早支持基于轻量 SDK + Mesh 的方式接管网格流量。目前主要支持 3 种流量劫持方式:轻量级 SD...
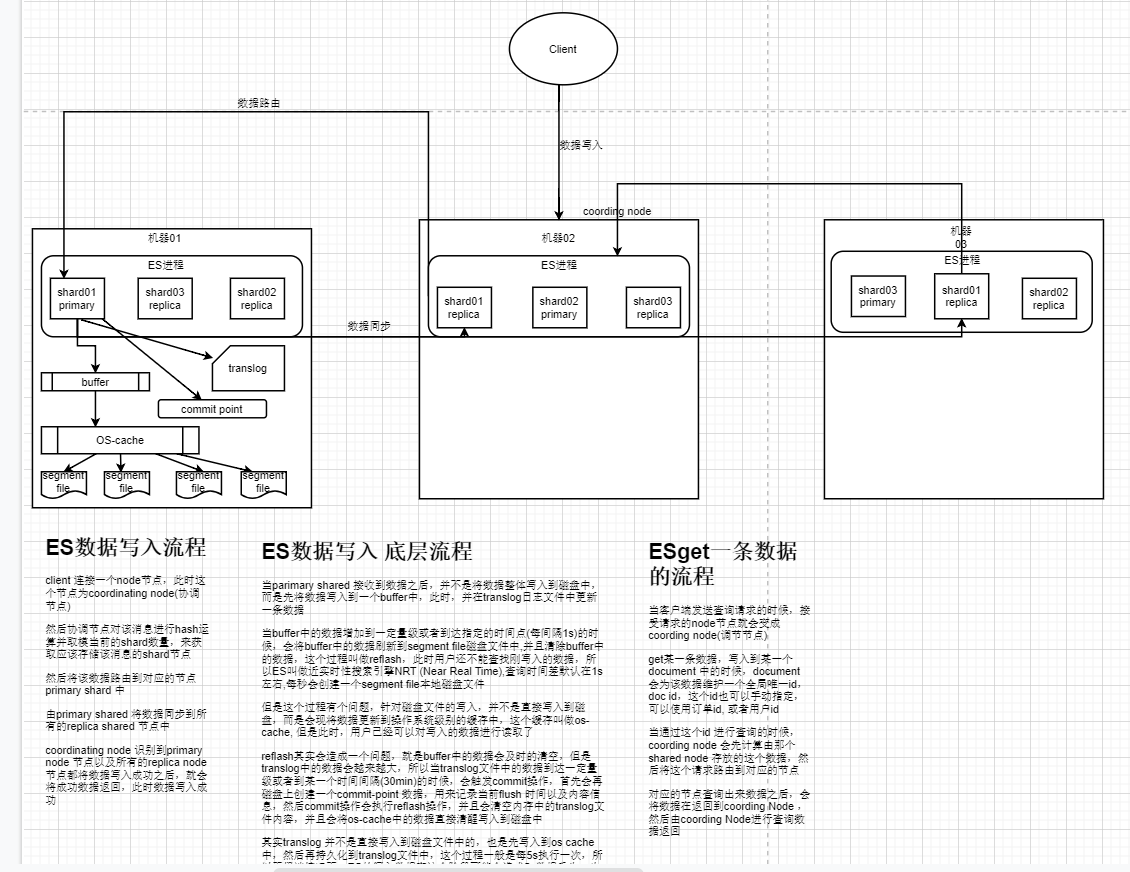
分布式搜索引擎(四) ES工作原理
ES写入数据的工作原理 客户端选择一个node发送请求过去,接受数据的这个node在此时相当于coordinating node(协调节点) coordinating node首先会对该消息进行hash运算,然后拿hash运算后的值取模,来计算该条数据应存放的shard节点,计算出来这个shard节点之后,会将数据路由到对应的parmary shard节点 然后由primary nod...
17、Python快速开发分布式搜索引擎Scrapy精讲—深度优先与广度优先原理
【http://www.lqkweb.com】 【http://www.swpan.cn】 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认是深度优先的 广度优先 是以层级来执行的,(列队方式实现) 【转载自:http://www.lqkweb.com】

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
分布式原理相关内容
- 分布式机器学习原理
- 分布式原理优化策略
- 分布式原理策略
- 分布式原理实践
- 分布式原理流程
- flink分布式快照原理
- 分布式快照原理
- 分布式hdfs原理
- 分布式原理存储
- rocketmq分布式原理
- 分布式id原理
- 分布式技术技术架构原理
- 分布式分析原理
- 分布式技术原理开发分析
- 分布式技术分布式事务原理
- 分布式技术原理开发
- 分布式技术原理方案
- 分布式原理分析
- 分布式组件原理分析
- 分布式组件原理
- 分布式技术原理分析
- 分布式解决方案原理
- 分布式原理机制
- 分布式协议原理
- 分布式zookeeper原理
- zookeeper分布式原理
- zookeeper分布式原理学习
- 分布式原理模式
- 分布式日志原理
- 分布式负载均衡原理
分布式更多原理相关

阿里云分布式应用服务
企业级分布式应用服务 EDAS(Enterprise Distributed Application Service)是应用全生命周期管理和监控的一站式PaaS平台,支持部署于 Kubernetes/ECS,无侵入支持Java/Go/Python/PHP/.NetCore 等多语言应用的发布运行和服务治理 ,Java支持Spring Cloud、Apache Dubbo近五年所有版本,多语言应用一键开启Service Mesh。
+关注