
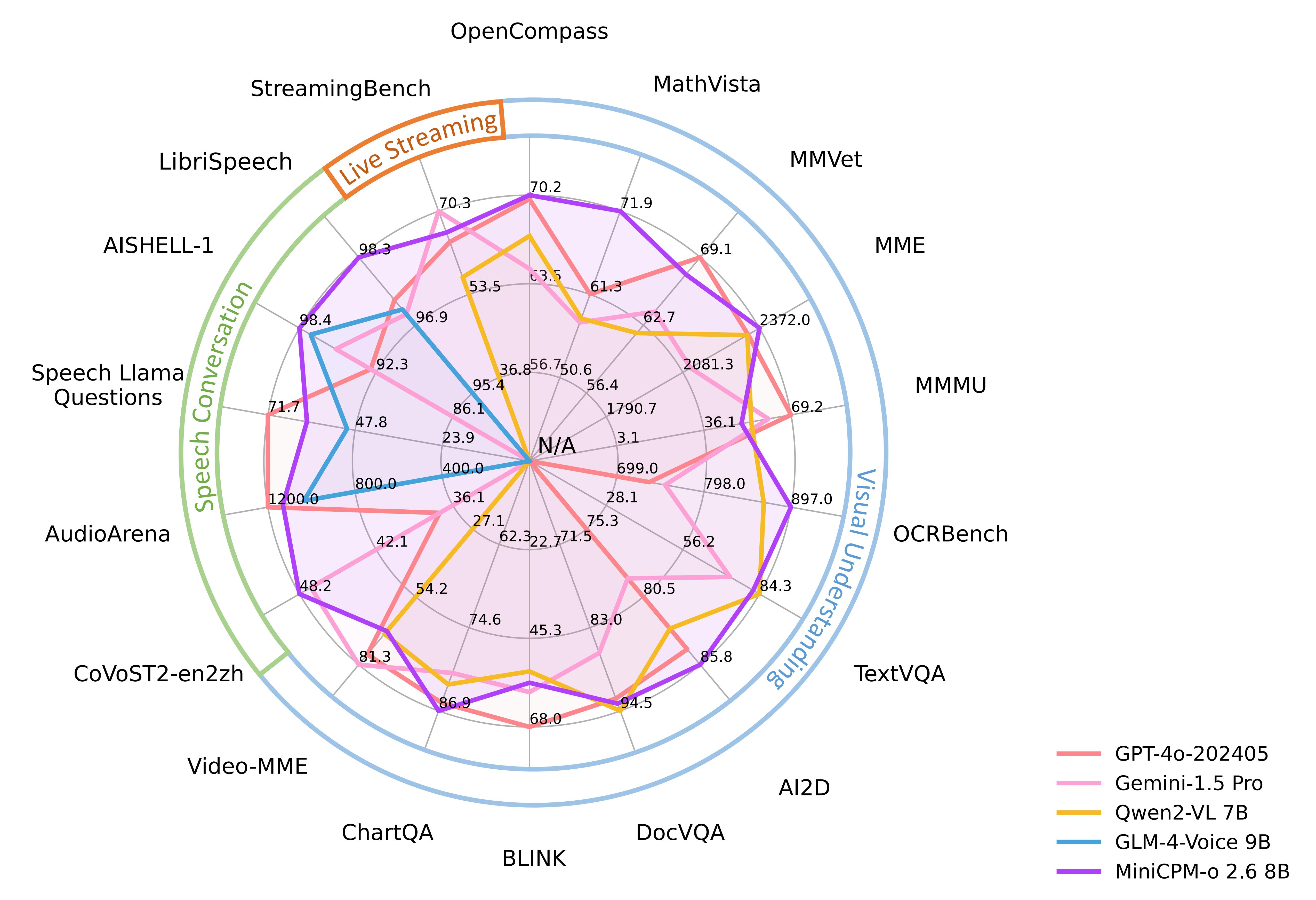
MiniCPM-o 2.6:面壁智能开源多模态大模型,仅8B参数量就能媲美GPT-4o,支持实时交互,在ipad等终端设备上运行
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦! 微信公众号|搜一搜:蚝油菜花 快速阅读 性能表现:MiniCPM-o 2.6 在视觉、语音和多模态直播领域表现出色,性能媲美GPT-4o。 功能特点:支持实时双语语音识别、情感/语速/风格控制、端...
商汤、清华、复旦等开源百亿级多模态数据集,可训练类GPT-4o模型
近日,商汤科技、清华大学、复旦大学等机构联合开源了一个名为OmniCorpus的多模态数据集,其规模达到了惊人的百亿级。这一数据集的发布,有望为训练类似GPT-4级别的大型多模态模型提供有力支持。 OmniCorpus数据集由多个图像和文本组成,以自然文档的形式排列,这种图像-文本交错的数据形式与互联网数据的呈现方式相一致&#...
多模态LLM视觉推理能力堪忧,浙大领衔用GPT-4合成数据构建多模态基准
随着大型语言模型(LLM)的迅速发展,多模态大型模型(MLLM)在视觉理解和推理任务中的应用也受到了广泛关注。然而,尽管MLLM在自然图像处理方面取得了显著进展,但在复杂和精细的图像类型(如图表、文档和图解)的理解上仍存在挑战。 近期,由浙江大学领衔的一支研...
清华领衔发布多模态评估MultiTrust:GPT-4可信度有几何?
近日,清华大学联合多家机构发布了一项名为MultiTrust的多模态评估研究,旨在全面评估多模态大型语言模型(MLLMs)的可信度。这项研究由清华大学计算机系的Yichi Zhang、Yao Huang、Yitong Sun等学者共同完成,并得到了来自北京航空航天大学、上海交通大学等机构的支持。 MultiTrust是第一个全...
Bengio团队提出多模态新基准,直指Claude 3.5和GPT-4o弱点
加拿大蒙特利尔大学的Yoshua Bengio团队最近提出了一个新的名为Multimodal Fewshot Evaluation(MFE)的多模态基准测试,该基准旨在评估大型语言模型在处理多模态任务时的能力。这一研究的提出,为我们深入了解和比较当前最先进的多模态模型提供了新的视角。 首先,让我们来看看MFE基准测试的背景和动...
首个多模态视频竞技场Video-MME来了!Gemini全面超越GPT-4o,Jeff Dean连转三次
在人工智能领域,多模态大模型(Multi-modal Large Language Models,MLLMs)被视为迈向通用人工智能(AGI)的重要一步。然而,尽管这些模型在静态图像理解方面取得了显著进展,但它们在处理连续视觉数据(如视频)方面的潜力仍待充分...
LeCun谢赛宁首发全新视觉多模态模型,等效1000张A100干翻GPT-4V
最近,人工智能领域的一项重要研究引起了广泛关注。由Facebook AI实验室的LeCun和Xie领导的团队,以及来自纽约大学的研究人员,共同发布了一种名为Cambrian-1的新型视觉多模态大语言模型(MLLM)。 Cambrian-1的发布标志着人工智能领域的一个重要里程碑。该模型旨在通过将强大的语言模型与先进的视觉组件相...
8B文字多模态大模型指标逼近GPT4V,字节、华师、华科联合提出TextSquare
在人工智能领域,多模态大模型的发展一直备受关注。最近,由字节跳动、华东师范大学和华中科技大学联合研究团队提出的TextSquare模型,在文字多模态视觉问答(VQA)任务上取得了令人瞩目的成绩。 TextSquare模型是一种基于大规模语言模型的文本中心视觉问答模型。它通过使用一种名为Square-10M的大规模、高质量指令微...
高性能计算与多模态处理的探索之旅:英伟达GH200性能优化与GPT-4V的算力加速未来
★多模态大模型;GPU算力;LLMS;LLM;LMM;GPT-4V;GH200;图像识别;目标定位;图像描述;视觉问答;视觉对话;英伟达;Nvidia;H100;L40s;A100;H100;A800;H800,AI算力,AI算法随着人工智能技术的不断发展,多模态大模型成为越来越重要的发展趋势。多模态大模型通过融合视觉等多种感知能力来扩展语言模型,实现更强大的通用人工智能。GPT-4V(GPT-....

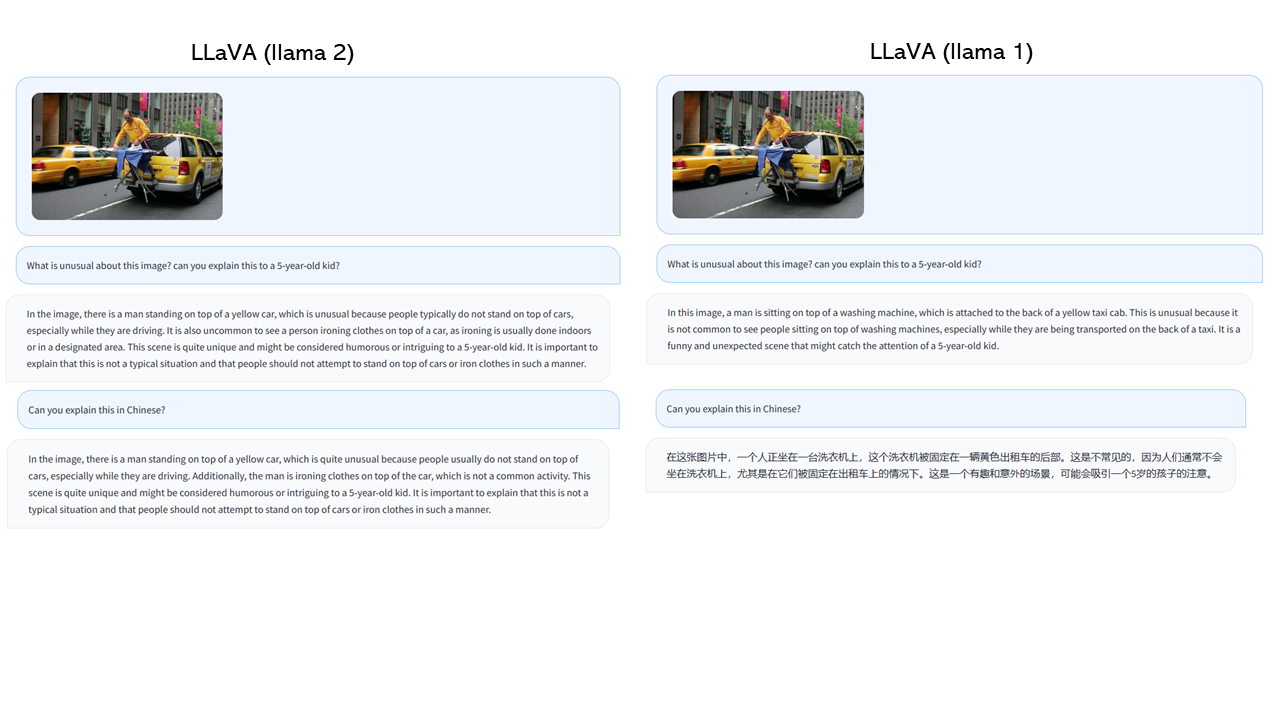
大规模语言LLaVA:多模态GPT-4智能助手,融合语言与视觉,满足用户复杂需求
大规模语言LLaVA:多模态GPT-4智能助手,融合语言与视觉,满足用户复杂需求一个面向多模式GPT-4级别能力构建的助手。它结合了自然语言处理和计算机视觉,为用户提供了强大的多模式交互和理解。LLaVA旨在更深入地理解和处理语言和视觉信息,从而实现更复杂的任务和对话。这个项目代表了下一代智能助手的发展方向,它能够更好地理解和应对用户需求。效果展示demo链接:https://llava.hli....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。