
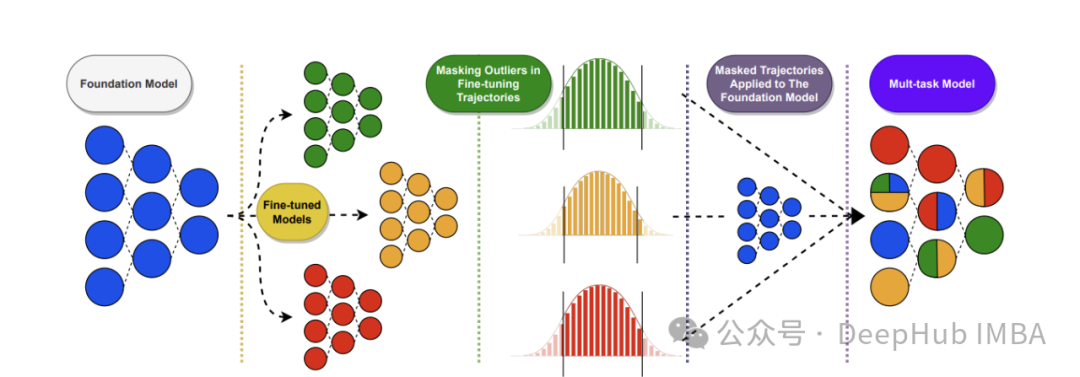
零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
随着大语言模型的快速发展,如何在不消耗大量计算资源的情况下优化模型性能成为业界关注焦点。模型权重合并技术提供了一种零训练成本的高效解决方案,能够智能整合多个专业微调模型的优势,无需额外训练即可显著提升性能表现。本文系统剖析11种前沿权重合并策略的理论基础与数学原理,从简单的线性插值到复杂的几何映射方法,并通过开源工具MergeKit提供详细的实战配置示例。无论您是AI研究人员寻求最优参数组合,企....
基于Dify +Ollama+ Qwen2 完成本地 LLM 大模型应用实战
本文原文链接 尼恩:LLM大模型学习圣经PDF的起源 在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。 经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。 然而,其中一个成功案例,是一个9年经验...

LLM-05 大模型 15分钟 FineTuning 微调 ChatGLM3-6B(微调实战1) 官方案例 3090 24GB实战 需22GB显存 LoRA微调 P-TuningV2微调
续接上节 我们的流程走到了,环境准备完毕。 装完依赖之后,上节结果为: 介绍LoRA LoRA原理 LoRA的核心思想是在保持预训练模型的大部分权重参数不变的情况下,通过添加额外的网络层来进行微调。这些额外的网络层通常包括两个线性层,一个用于将数据从较高维度降到...

LLM-04 大模型 15分钟 FineTuning 微调 ChatGLM3-6B(准备环境) 3090 24GB实战 需22GB显存 LoRA微调 P-TuningV2微调
背景介绍 ChatGLM3是由智谱AI和清华大学KEG实验室联合开发的一款新一代对话预训练模型。这个模型是ChatGLM系列的最新版本,旨在提供更流畅的对话体验和较低的部署门槛。ChatGLM3-6B是该系列中的一个开源模型,它继承了前两代模型的优秀特性,并引入了一些新的功能和改进。 基础模型性能提升:ChatGLM3-6B基于更多样的训练数据、更充分的训练步数和更合理...

LLM-03 大模型 15分钟 FineTuning 微调 GPT2 模型 finetuning GPT微调实战 仅需6GB显存 单卡微调 数据 10MB数据集微调
参考资料 GPT2 FineTuning OpenAI-GPT2 Kaggle short-jokes 数据集 Why will you need fine-tuning an LLM? LLMs are generally trained on public data with no specific focus. Fine-tuning is a cr...

LLM大模型部署实战指南:Ollama简化流程,OpenLLM灵活部署,LocalAI本地优化,Dify赋能应用开发
LLM大模型部署实战指南:Ollama简化流程,OpenLLM灵活部署,LocalAI本地优化,Dify赋能应用开发 1. Ollama 部署的本地模型() Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。,这是 Ollama 的官网地址:https://ollama.com/ 以下是其主要特点和功能概述: 简化部署:Ollam...
初识langchain:LLM大模型+Langchain实战[qwen2.1、GLM-4]+Prompt工程
初识langchain:LLM大模型+Langchain实战[qwen2.1、GLM-4]+Prompt工程 1.大模型基础知识 大模型三大重点:算力、数据、算法,ReAct (reason推理+act行动)--思维链 Langchain会把上述流程串起来,通过chain把多个算法模型串联起来 Langchain的 I/O系统,负责输入输出管理【文件形式加载提示词】 ...
![初识langchain:LLM大模型+Langchain实战[qwen2.1、GLM-4]+Prompt工程](https://ucc.alicdn.com/fnj5anauszhew_20240719_85e2ec2d8f98458dbd7eaa93b64fdf7e.png)
LLM代理应用实战:构建Plotly数据可视化代理
如果你尝试过像ChatGPT这样的LLM,就会知道它们几乎可以为任何语言或包生成代码。但是仅仅依靠LLM是有局限的。对于数据可视化的问题我们需要提供一下的内容 描述数据:模型本身并不知道数据集的细节,比如列名和行细节。手动提供这些信息可能很麻烦,特别是当数据集变得更大时。如果没有这个上下文,LLM可能会产生幻觉或虚构列名,从而导致数据可视化中的错误。 样式和偏好:数据可视化是一种艺术形式,每...

LLM应用实战:当图谱问答(KBQA)集成大模型(三)
1. 背景 最近比较忙(也有点茫),本qiang~想切入多模态大模型领域,所以一直在潜心研读中... 本次的更新内容主要是响应图谱问答集成LLM项目中反馈问题的优化总结,对KBQA集成LLM不熟悉的客官可以翻翻之前的文章《LLM应用实战:当KBQA集成LLM》、《LLM应用实战:当KBQA集成LLM(二)》。 针对KBQA集成LLM项目,该系列文章主要是通过大模型来代替传...
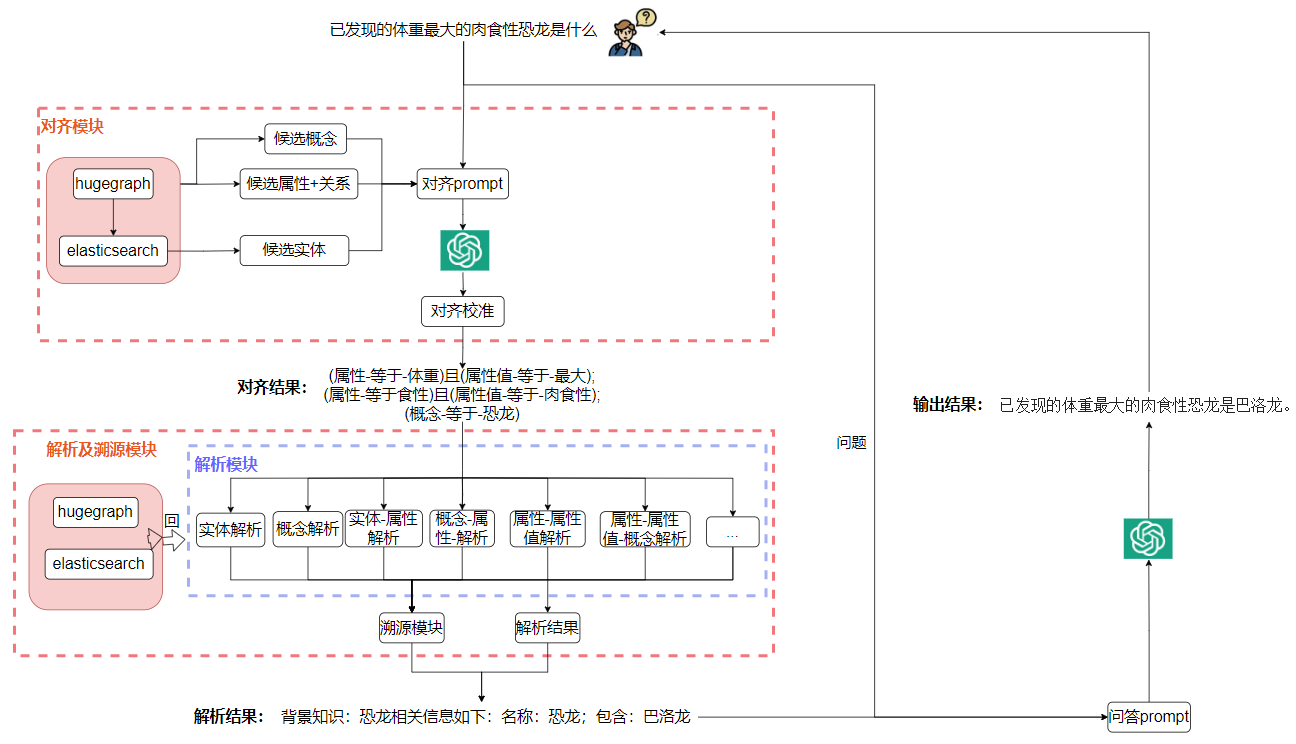
LLM应用实战:当KBQA集成LLM(二)
1. 背景 又两周过去了,本qiang~依然奋斗在上周提到的项目KBQA集成LLM,感兴趣的可通过传送门查阅先前的文章《LLM应用实战:当KBQA集成LLM》。 本次又有什么更新呢?主要是针对上次提到的缺点进行优化改进。主要包含如下方面: 1. 数据落库 上次文章提到,KBQA服务会将图谱的概念、属性、实体、属性值全部加载到内存,所有的查询均在内存中进行,随之而来...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
