
放行搜索引擎爬虫
为了避免等候室的排队机制对主流搜索引擎的SEO和搜索结果产生影响,您可以启用放行搜索引擎爬虫功能,使经过Bot Management验证的SEO爬虫程序可以绕过等候室直接访问您的源站资源。
在Kotlin中设置User-Agent以模拟搜索引擎爬虫
前言随着双十一电商活动的临近,电商平台成为了狂欢的中心。对于商家和消费者来说,了解市场趋势和竞争对手的信息至关重要。在这个数字时代,爬虫技术成为了获取电商数据的有力工具之一。本文将以亚马逊为例,介绍如何使用Kotlin编写一个爬虫程序,通过设置User-Agent头部来模拟搜索引擎爬虫,从而成功抓取亚马逊的商品信...
搜索引擎爬虫的工作原理是什么?底层原理是什么?
搜索引擎爬虫(Spider)是搜索引擎的重要组成部分,主要负责从互联网上抓取网页内容,并将其存储到搜索引擎的数据库中,以便后续的索引和检索。搜索引擎爬虫的工作原理通常包括以下几个步骤:确定抓取范围:爬虫程序首先需要确定需要抓取的网页范围,一般是从搜索引擎的数据库中获取待抓取的网页 URL。抓取网页内容:爬虫程序通过 HTTP 协议向网站发送请求,获取网页内容,并将其存储到搜索引擎的数据库中。解析....
24、Python快速开发分布式搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
【百度云搜索:http://www.lqkweb.com】 【搜网盘:http://www.swpan.cn】 1、基本概念 2、反爬虫的目的 3、爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图

2019年最新出搜索引擎蜘蛛网页爬虫大全
2019年最新出搜索引擎蜘蛛网页爬虫大全分享,各大seo引擎搜索的蜘蛛会一次又一次访问爬取我们站点的文章内容,也会耗费一定的站点流量; 有时候就必须屏蔽一些蜘蛛浏览我们的站点,文章尾部会讲解决方案; 掌握各大搜索引擎蜘蛛爬虫,对我们开展网站SEO优化具有挺大作用;作者搜集了各大搜索引擎的蜘蛛爬虫UA,便于你需要时查看。1、百度蜘蛛:BaiduSpider 常见的Baiduspider和Baidu....
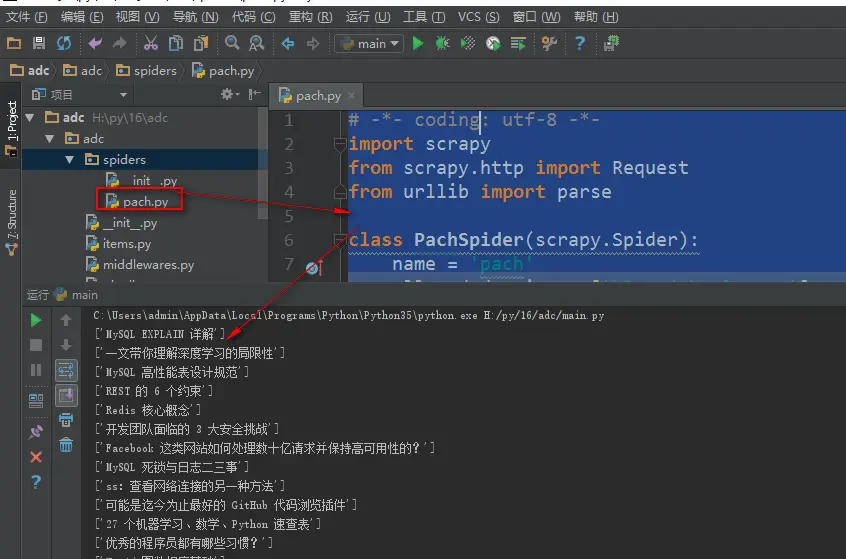
23、 Python快速开发分布式搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
转: http://www.bdyss.cn http://www.swpan.cn 用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates:母版说明 basic 创建基础爬虫文件 crawl ...
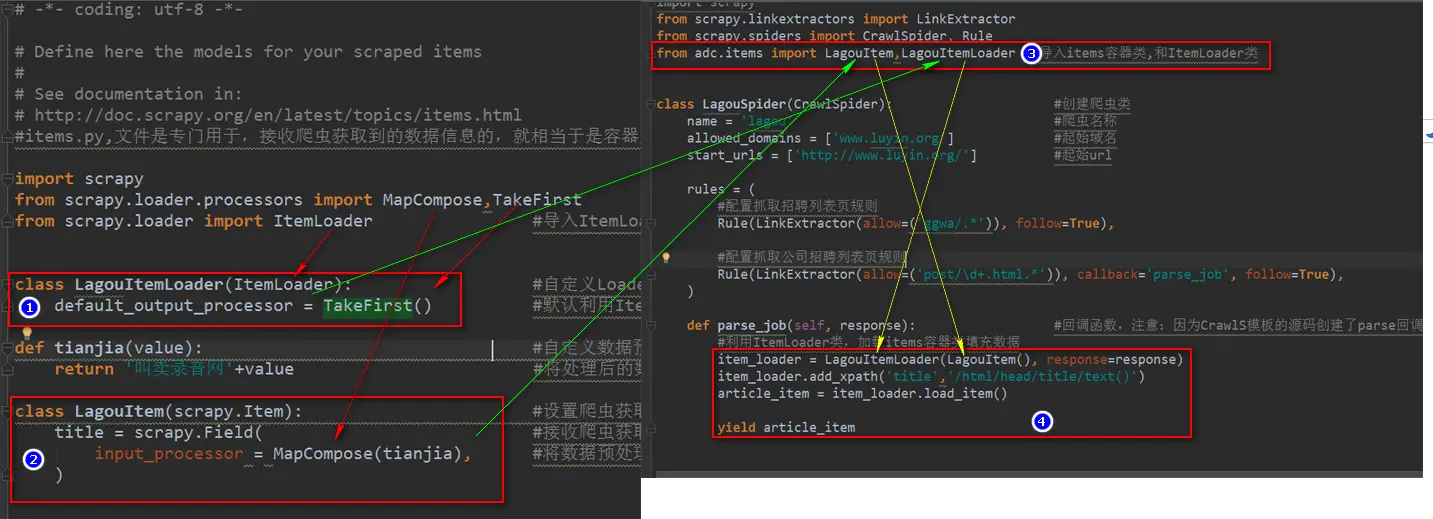
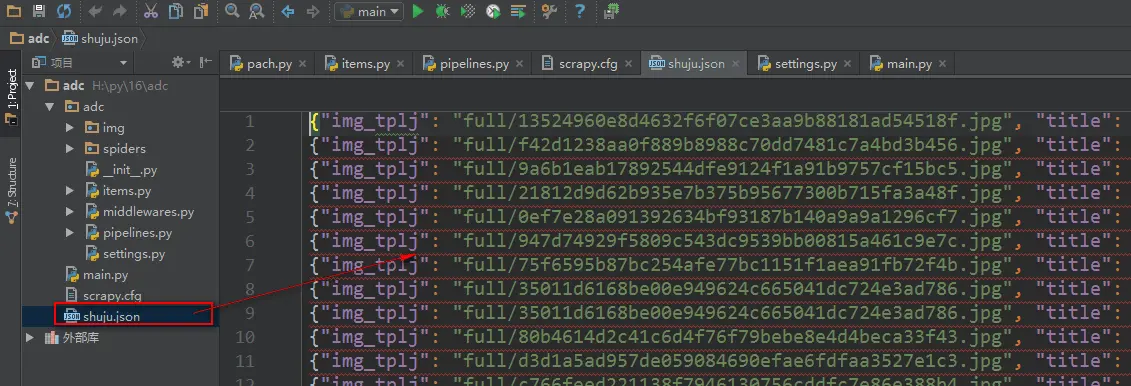
21、 Python快速开发分布式搜索引擎Scrapy精讲—爬虫数据保存
注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 # -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to&nbs...
20、 Python快速开发分布式搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield Request() parse.urljoin()方法,是urllib库下的方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接 # -*- ...
各大搜索引擎蜘蛛爬虫的UA
月小升在了解各大搜索引擎蜘蛛爬虫的UA,对自己进行某些程序编写十分有用,例如网页判断客户端来源时,UA是常用的标准之一。本文收集了各大搜索引擎的蜘蛛爬虫UA,以便需要时查阅。我也在思考是否要给java-er.com设置个头,不过我目前还没有搜索引起,所以也无所谓了。 Google “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.goog.....
Web网站如何查看搜索引擎蜘蛛爬虫的行为
简介 本文给大家介绍Linux/Nginx如何查看搜索引擎蜘蛛爬虫的行为,清楚蜘蛛的爬行情况对做SEO优化有很大的帮助。需要的朋友通过本篇文章学习下吧 摘要 做好网站SEO优化的第一步就是首先让蜘蛛爬虫经常来你的网站进行光顾,下面的Linux命令可以让你清楚的知道蜘蛛的爬行情况。 下面我们针对nginx服务器进行分析,日志文件所在目录 /usr/local/nginx/logs/acc...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注