
如何配置API数据服务
DataWorks的数据服务模块,提供了通过API消费数据的服务,可以为使用API接收数据的业务提供数据。本文将以场景示例形式,为您介绍如何用DataWorks完成API服务对数据的消费。
如何配置API数据服务
DataWorks的数据服务模块,提供了通过API消费数据的服务,可以为使用API接收数据的业务提供数据。本文将以场景示例形式,为您介绍如何用DataWorks完成API服务对数据的消费。
如何配置API数据服务
DataWorks的数据服务模块,提供了通过API消费数据的服务,可以为使用API接收数据的业务提供数据。本文将以场景示例形式,为您介绍如何用DataWorks完成API服务对数据的消费。
HBase在线迁移数据
本方案通过结合HBase Snapshot和HBase Replication技术,在源端HBase集群不停服的情况下,实现存量数据和增量数据的在线迁移,确保迁移过程中数据无丢失。
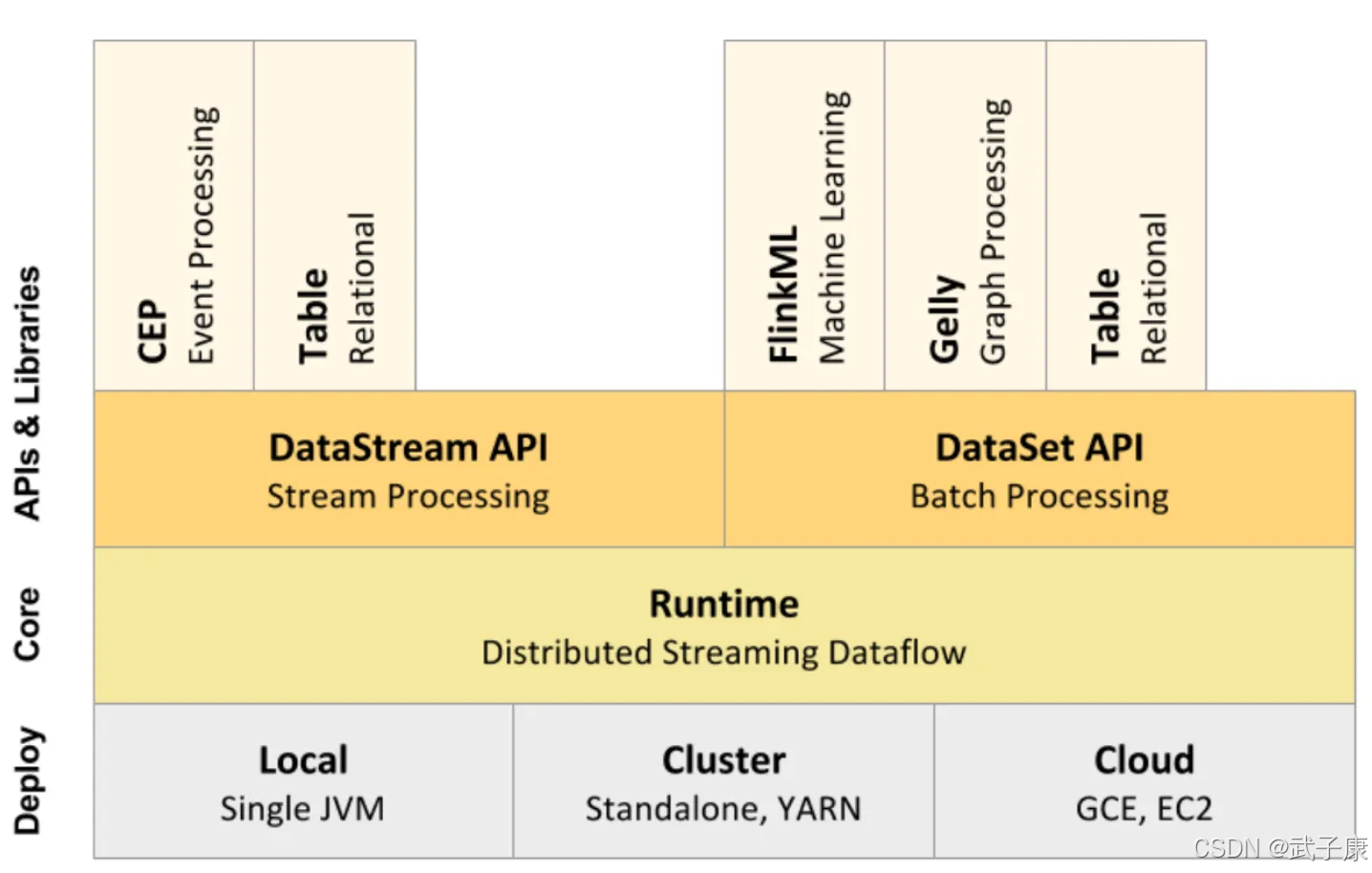
大数据-108 Flink 快速应用案例 重回Hello WordCount!方案1批数据 方案2流数据(一)
点一下关注吧!!!非常感谢!!持续更新!!!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume&...
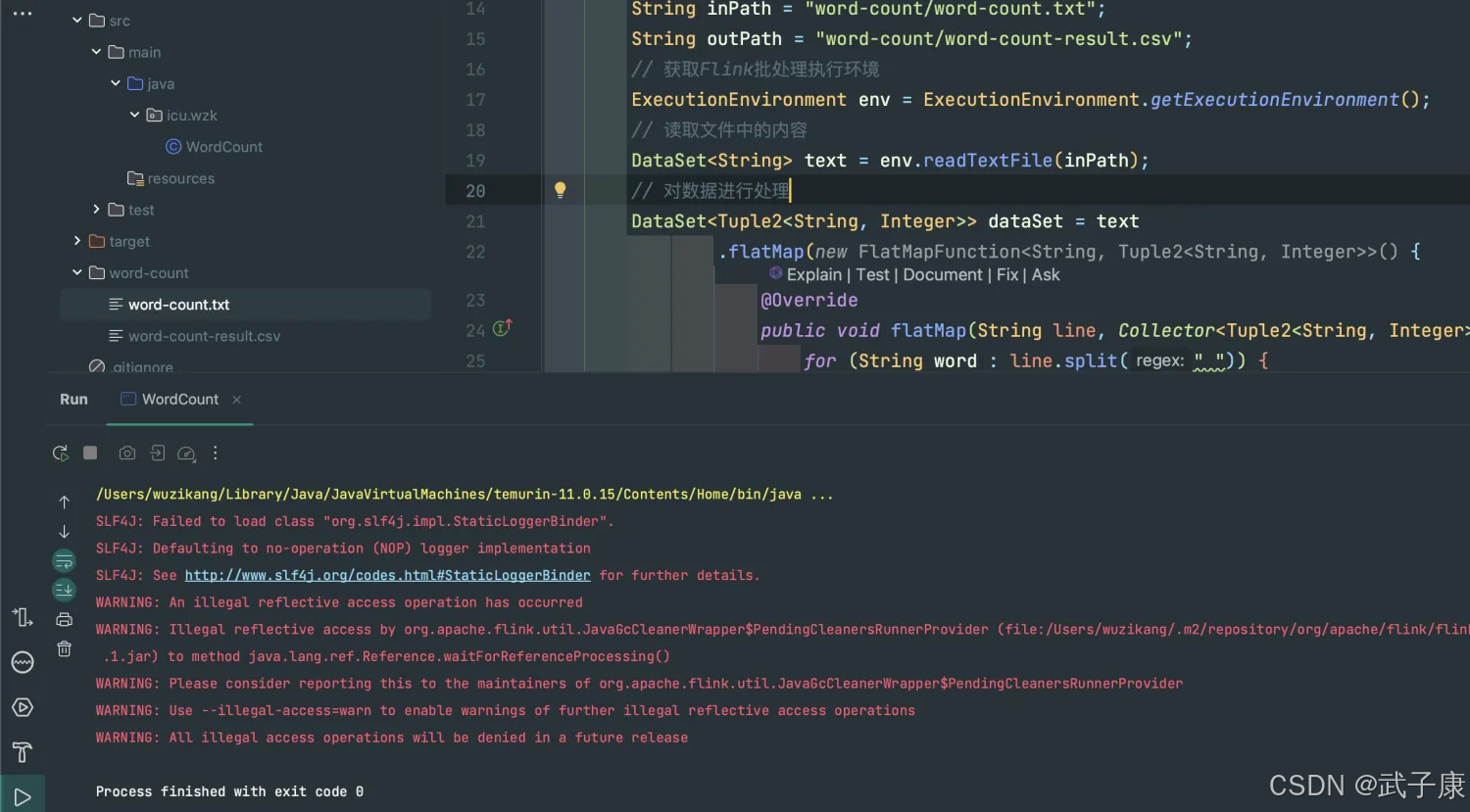
大数据-108 Flink 快速应用案例 重回Hello WordCount!方案1批数据 方案2流数据(二)
接上篇:https://developer.aliyun.com/article/1622681?spm=a2c6h.13148508.setting.17.27ab4f0ek8nPMY 运行测试 结果数据 查看 word-count/word-count-result.csv...
大数据计算MaxCompute有其他经济方案可以将MaxCompute的数据以API形式输出吗?
大数据计算MaxCompute独享传输资源组成本太高,有其他经济方案可以将MaxCompute的数据以API形式输出吗?
大家好,业务中遇到了大数据量(接近百万级)的数据导出成excel/csv,之前的方案是java应用从mysql查出数据,poi生成excel,在pg有没有更好的方案?有七八十万的导出场景
喜爱PostgresSQL的同学扫码进群
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute数据相关内容
- 数据科学云原生大数据计算服务 MaxCompute
- 数据云原生大数据计算服务 MaxCompute实战
- 数据云原生大数据计算服务 MaxCompute分析
- 智能数据云原生大数据计算服务 MaxCompute
- 工具数据云原生大数据计算服务 MaxCompute
- 同步云原生大数据计算服务 MaxCompute数据
- 大数据计算云原生大数据计算服务 MaxCompute数据
- dataworks云原生大数据计算服务 MaxCompute数据
- 数据云原生大数据计算服务 MaxCompute挖掘
- 数据云原生大数据计算服务 MaxCompute专家
- 云原生大数据计算服务 MaxCompute数据外表
- spark云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute分析数据技术
- 云原生大数据计算服务 MaxCompute数据处理数据
- 云原生大数据计算服务 MaxCompute数据技术
- 云原生大数据计算服务 MaxCompute分区数据
- 数据资产云原生大数据计算服务 MaxCompute
- maxcompute云原生大数据计算服务 MaxCompute数据
- 查询云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute优化数据
- 数据云原生大数据计算服务 MaxCompute技术
- 数据云原生大数据计算服务 MaxCompute企业
- 数据治理云原生大数据计算服务 MaxCompute数据质量
- 云原生大数据计算服务 MaxCompute技术数据
- 云原生大数据计算服务 MaxCompute测试数据
- 云原生大数据计算服务 MaxCompute kylin数据
- 云原生大数据计算服务 MaxCompute apache数据
- 云原生大数据计算服务 MaxCompute构建数据
- 云原生大数据计算服务 MaxCompute flink数据
- 云原生大数据计算服务 MaxCompute学习数据
云原生大数据计算服务 MaxCompute更多数据相关
- 产品云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute数据增量
- 云原生大数据计算服务 MaxCompute数据分区表
- 云原生大数据计算服务 MaxCompute数据odps
- 云原生大数据计算服务 MaxCompute数据步骤
- 云原生大数据计算服务 MaxCompute增量数据
- 数据云原生大数据计算服务 MaxCompute价值
- 数据计算云原生大数据计算服务 MaxCompute离线同步数据
- 数据计算云原生大数据计算服务 MaxCompute数据导出
- 数据计算云原生大数据计算服务 MaxCompute数据oss
- 云原生大数据计算服务 MaxCompute产品数据
- 云原生大数据计算服务 MaxCompute tunnel数据
- 云原生大数据计算服务 MaxCompute下载数据
- 云原生大数据计算服务 MaxCompute sql数据
- 云原生大数据计算服务 MaxCompute查询数据
- 云原生大数据计算服务 MaxCompute数据报错
- dataworks数据云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute外部表数据
- 云原生大数据计算服务 MaxCompute任务数据
- 云原生大数据计算服务 MaxCompute命令数据
- 云原生大数据计算服务 MaxCompute存储数据
- 云原生大数据计算服务 MaxCompute pyodps数据
- 云原生大数据计算服务 MaxCompute模型数据
- 云原生大数据计算服务 MaxCompute数据配置
- 云原生大数据计算服务 MaxCompute数据oss
- 云原生大数据计算服务 MaxCompute分区表数据
- 云原生大数据计算服务 MaxCompute tunnel命令数据
- 云原生大数据计算服务 MaxCompute spark数据
- 云原生大数据计算服务 MaxCompute tunnel下载数据
- 云原生大数据计算服务 MaxCompute类型数据
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute解析
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute操控
- 云原生大数据计算服务 MaxCompute工具
- 云原生大数据计算服务 MaxCompute较量
- 云原生大数据计算服务 MaxCompute温度
- 云原生大数据计算服务 MaxCompute数据链路
- 云原生大数据计算服务 MaxCompute预测性维护
- 云原生大数据计算服务 MaxCompute故障
- 云原生大数据计算服务 MaxCompute设备
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
