
用户画像分析案例同步数据-基于新版数据开发和Spark计算资源
本文将介绍如何创建HttpFile和MySQL数据源以访问用户信息和网站日志数据,配置数据同步链路将这些数据同步到在环境准备阶段创建的OSS存储中,并通过创建Spark外表解析OSS中存储的数据。通过查询验证数据同步结果,确认是否完成整个数据同步操作。
DataWorks中如何同步数据至EMR Serverless Spark
本教程以MySQL数据源中的用户基本信息ods_user_info_d表和HttpFile中的网站访问日志数据user_log.txt文件为例,通过数据集成离线同步任务分别同步至私有OSS中,再通过Spark SQL创建外部表来访问私有OSS数据存储。本章节旨在完成数据同步操作。
实时计算 Flink版产品使用问题之同步到Hudi的数据是否可以被Hive或Spark直接读取
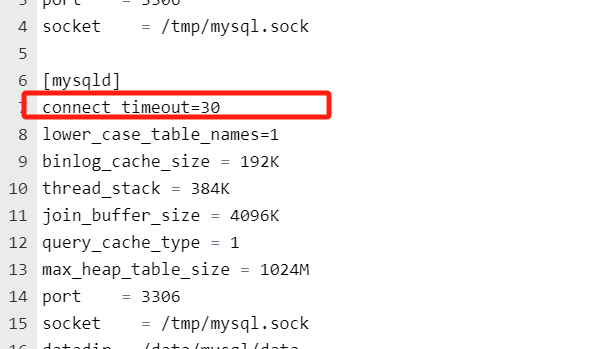
问题一:Flink CDC这个应该在哪里配? Flink CDC这个应该在哪里配?mysql 的超时我已经改成30s了 参考答案: 要么找DBA改一下,要么自己去看有没有参数改,我们是10分钟,有的...
Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Dataworks同步数据到X-pack Spark
简介本文主要介绍如何通过“Dataworks->数据集成->离线同步”把数据同步到X-pack Spark的hdfs上。同步数据到X-pack的hdfs后,就可以使用X-pack Spark对数据进行分析。本例通过把Dataworks的一张表同步到X-pack Spark的hadfs为例,介绍如何同步数据。前置条件X-pack Spark集群已经开通hdfs端口。需要联系X-pack....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark系统
- apache spark技术
- apache spark大数据
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark yarn
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注