
蓝易云 - crawlab通过docker单节点部署简单爬虫
rawlab是一个基于Golang的分布式爬虫管理平台,支持Python、NodeJS、Go、Java、PHP、Ruby等多种语言以及各种爬虫框架。以下是通过Docker单节点部署Crawlab并运行简单爬虫的步骤: 安装Docker和Docker Compose。Docker是一个开源的应用容器引擎,Docker Compose是一个用于定义和运行多容...
Python爬虫:scrapy从项目创建到部署可视化定时任务运行
目录前言第一节 基本功能1、使用 pyenv创建虚拟环境2、创建 scrapy项目3、创建爬虫第二节 部署爬虫4、启动 scrapyd5、使用 scrapyd-client 部署爬虫项目6、使用 spider-admin-pro管理爬虫第三节 部署优化7、使用 Gunicorn管理应用8、使用 supervisor管理进程9、使用 Nginx转发请求前言前面1-3小节就是基本功能实现,完成了sc....

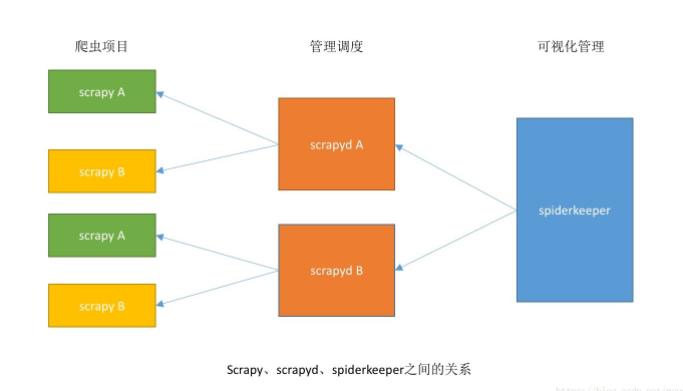
python爬虫:scrapy可视化管理工具spiderkeeper部署
需要安装的库比较多,可以按照步骤,参看上图理解环境准备scrapy: https://github.com/scrapy/scrapyscrapyd: https://github.com/scrapy/scrapydscrapyd-client: https://github.com/scrapy/scrapyd-clientSpiderKeeper: https://github.com/D....
使用云服务器ECS部署了自己的第一个爬虫
1.背景 由于考研复试需要实时获取报考学校的最新通知,以免错过重要的消息,而手动刷新的方式费时费力,因此想到通过爬虫实现实时获取最新通知的功能。但还需解决几个问题:爬虫爬取的最新通告,采用什么方式推送爬虫爬取的频率设置为多快爬虫应该部署在哪里 对于上述的几个问题,经过一番研究后,得出了结论....
Scrapy框架-通过Scrapyd来部署爬虫
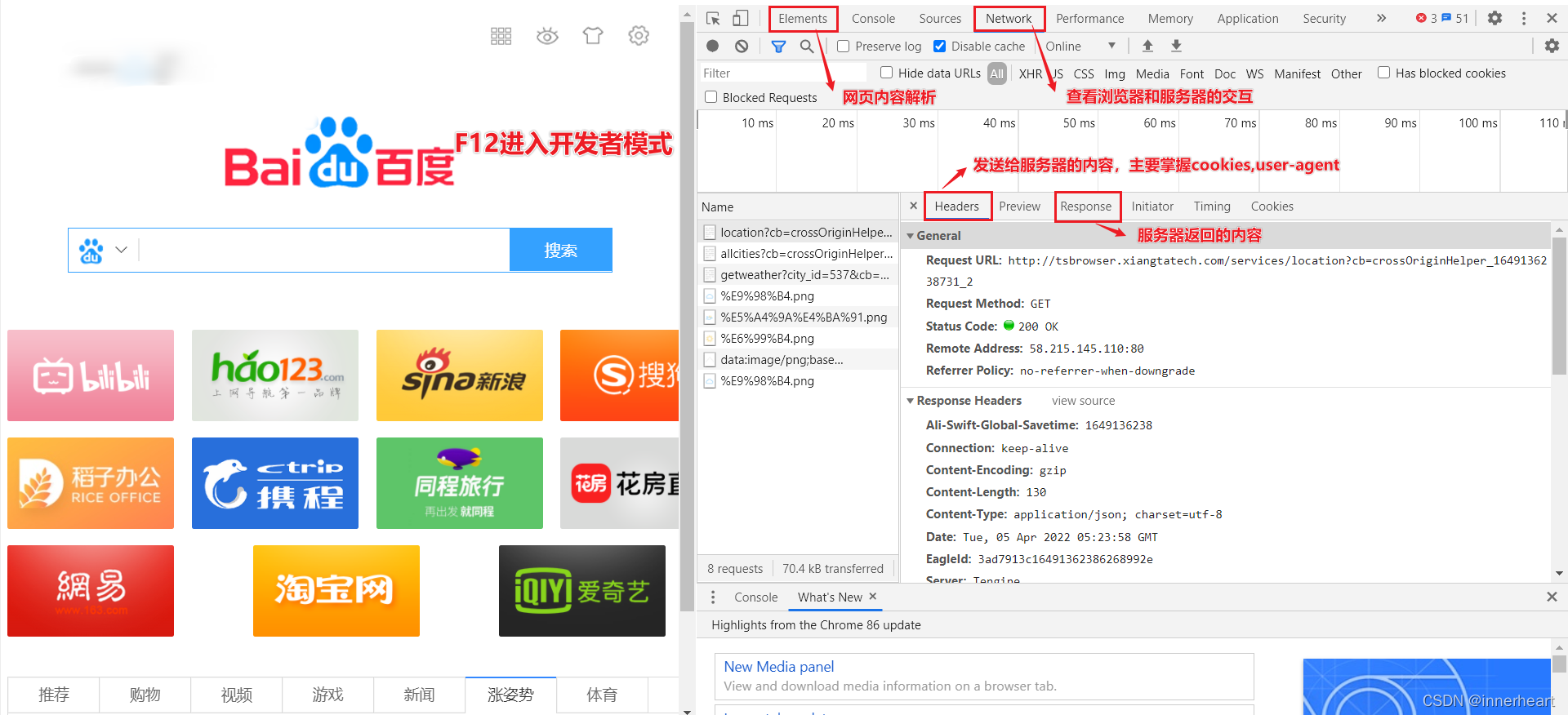
前言 爬虫写完了,很多时候本机部署就可以了,但是总有需要部署到服务器的需求,网上的文章也比较多,复制的也比较多,从下午3点钟摸索到晚上22点,这里记录一下。 环境情况 我的系统是Deepin 开发环境也是Deepin,python 环境用的是Anaconda建立的虚拟环境(python3.6) 部署系统是本机的Deepin 部署环境由于在本机部署,所以跟开发环境一致(就是这里有个坑) 用到的...
Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrapyd的github地址:https://github.com/scrapy/scrapyd 当在远程主机上安装了scrapyd并启动之后,就会再远程主机上启动一个web服务,默认是6800端口,这样....
部署了CDN,但是爬虫抓取仍然超时。
部署了CDN,但是在提交链接给百度搜索引擎的时候,百度抓取上显示抓取超时,部分链接偶尔有这种情况。用户是可以正常打开的。这是怎么回事呢?应如何优化CDN,让爬虫也可以更好的抓取到网站内容?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注