
「Python」爬虫-9.Scrapy框架的初识-公交信息爬取
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第23天, 点击查看活动详情Spider实战本文将讲解如何使用scrapy框架完成北京公交信息的获取。目标网址为https://beijing.8684.cn/。在前文的爬虫实战中,已经讲解了如何使用requests和bs4爬取公交站点的信息,感兴趣的话可以先阅读一下「Python」爬虫实战系列-北京公交线路信息爬取(...

13、web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
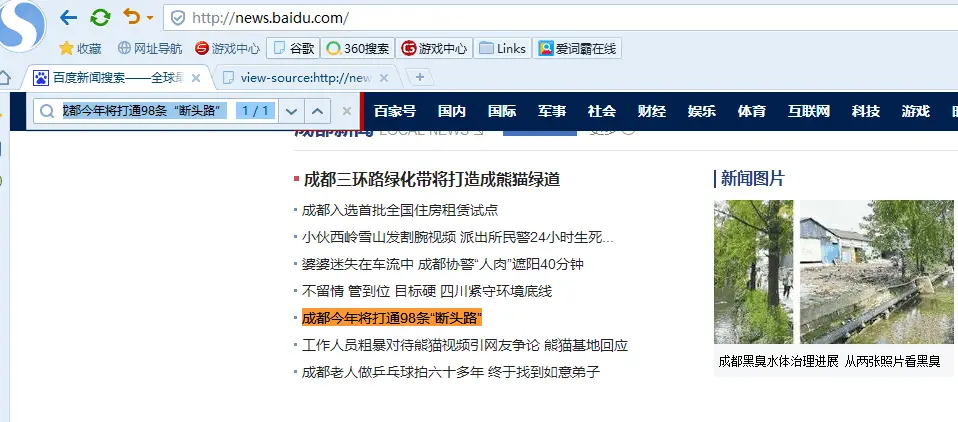
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息,那么这种一般都是 js 的 Ajax 动态请求生成的信息 我们以百度新闻为列: 1、分析网站 首先我们浏览器打开百度新闻,在网页中间部分找一条新闻信息 然后查看源码,看看在源码里是否有这条新...
爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。 如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。(推荐安装IPython) 1 ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
爬虫scrapy相关内容
- scrapy框架爬虫
- scrapy爬虫策略
- 爬虫框架scrapy
- scrapy爬虫应用
- 爬虫scrapy框架
- 爬虫scrapy数据
- scrapy爬虫自定义
- 爬虫开发scrapy
- 爬虫scrapy入门
- 爬虫scrapy爬取
- scrapy爬虫爬取数据
- scrapy爬虫数据
- scrapy爬虫爬取
- 配置scrapy爬虫
- 爬虫库scrapy
- 爬虫scrapy豆瓣
- 爬虫scrapy xpath
- 爬虫scrapy安装
- 爬虫scrapy管理工具
- 爬虫scrapy工具
- 爬虫scrapy功能
- 爬虫scrapy代理
- 爬虫scrapy爬虫框架
- 爬虫scrapy框架安装
- scrapy爬虫项目
- scrapy爬虫调试
- scrapy爬虫教程
- scrapy爬虫实例
- scrapy爬虫报错
- scrapy爬虫不报错
爬虫更多scrapy相关
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注