
用户画像分析案例同步数据-基于新版数据开发和Spark计算资源
本文将介绍如何创建HttpFile和MySQL数据源以访问用户信息和网站日志数据,配置数据同步链路将这些数据同步到在环境准备阶段创建的OSS存储中,并通过创建Spark外表解析OSS中存储的数据。通过查询验证数据同步结果,确认是否完成整个数据同步操作。
DataWorks中EMR Serverless Spark版本的用户画像分析的加工数据阶段
本文为您介绍如何用Spark SQL创建外部用户信息表ods_user_info_d_spark以及日志信息表ods_raw_log_d_spark访问存储在私有OSS中的用户与日志数据,通过DataWorks的EMR Spark SQL节点进行加工得到目标用户画像数据,阅读本文后,您可以了解如何通过Spark SQL来计算和分析已同步的数据,完成数仓简单数据加工场景。
用户画像分析案例加工数据-基于新版数据开发和Spark计算资源
本文为您介绍如何用Spark SQL创建外部用户信息表ods_user_info_d_spark以及日志信息表ods_raw_log_d_spark访问存储在私有OSS中的用户与日志数据,通过DataWorks的EMR Spark SQL节点进行加工得到目标用户画像数据,阅读本文后,您可以了解如何通过Spark SQL来计算和分析已同步的数据,完成数仓简单数据加工场景。
用户画像分析案例环境准备-基于新版数据开发和Spark计算资源
本教程以用户画像为例,在华东2(上海)地域演示如何使用DataWorks完成数据同步、数据加工和质量监控的全流程操作。为了确保您能够顺利完成本教程,您需要准备教程所需的EMR Serverless Spark空间、DataWorks工作空间,并进行相关的环境配置。
在TDX实例中基于BigDL PPML构建全链路安全的分布式Spark大数据分析应用
本文介绍在基于Intel® TDX安全特性的g8i实例中,使用BigDL PPML解决方案运行分布式的全链路安全的Spark大数据分析应用。
Spark计算过程分析
基本概念 Spark是一个分布式的内存计算框架,其特点是能处理大规模数据,计算速度快。Spark延续了Hadoop的MapReduce计算模型,相比之下Spark的计算过程保持在内存中,减少了硬盘读写,能够将多个操作进行合并后计算,因此提升了计算速度。同时Spark也提供了更丰富的计算API。 MapReduce是Hadoop和Spark的计算模型,其特点是Map和Reduce过程高度可并行化.....
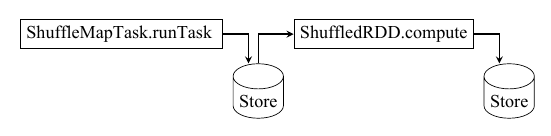
Apache Spark源码走读(十)ShuffleMapTask计算结果的保存与读取 &WEB UI和Metrics初始化及数据更新过程分析
<一>ShuffleMapTask计算结果的保存与读取 概要 ShuffleMapTask的计算结果保存在哪,随后Stage中的task又是如何知道从哪里去读取的呢,这个过程一直让我困惑不已。 用比较通俗一点的说法来解释一下Shuffle数据的写入和读取过程 每一个task负责处理一个特定的data partition task在初始化的时候就已经明确处理结果可能会产生多少个不同...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark分析相关内容
- apache spark分析应用
- apache spark出租车分析
- apache spark轨迹分析
- 分析apache spark
- 分析平台apache spark
- apache spark原理分析
- apache spark大规模分析
- apache spark数据集分析
- apache spark hudi分析
- apache spark概念分析
- apache spark分析源码
- apache spark kafka分析
- apache spark故障分析
- apache spark多数据源分析
- apache spark优化分析
- apache spark delta分析
- apache spark实现分析
- apache spark文件分析
- apache spark项目分析
- apache spark构建分析
- 大数据apache spark分析数据综合案例
- apache spark函数分析
- apache spark task分析
- apache spark hive分析
- apache spark分析商品
- 分析apache spark系统
- apache spark eu分析
- apache spark based shuffle分析
- x-pack apache spark分析
- apache spark通信分析
apache spark更多分析相关
apache spark您可能感兴趣
- apache spark训练
- apache spark特征
- apache spark实战
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark yarn
- apache spark技术
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注