
R语言广义线性混合模型GLMMs在生态学中应用可视化2实例合集|附数据代码2
R语言广义线性混合模型GLMMs在生态学中应用可视化2实例合集|附数据代码1:https://developer.aliyun.com/article/1501226 参数自助法似然比检验:对新的固定效应模型进行了参数自助法似然比检验。 # 模拟...

R语言广义线性混合模型GLMMs在生态学中应用可视化2实例合集|附数据代码1
在生态学研究领域,广义线性混合模型(Generalized Linear Mixed Models,简称GLMMs)是一种强大的统计工具,能够同时处理固定效应和随机效应,从而更准确地揭示生态系统中复杂关系的本质(点击文末“阅读原文”获取完整代码数据)。 随着数据分析技术的不断发展,R语言已成为生态学家们进行数据分析的首选工具之一,而GLMMs在R语言中的实现与应用也日益受到关注...

R语言SOM神经网络聚类、多层感知机MLP、PCA主成分分析可视化银行客户信用数据实例2
R语言SOM神经网络聚类、多层感知机MLP、PCA主成分分析可视化银行客户信用数据实例1:https://developer.aliyun.com/article/1501159 从结果中我们可以看到将数据划分成不同类别后得...
R语言SOM神经网络聚类、多层感知机MLP、PCA主成分分析可视化银行客户信用数据实例1
自组织地图(SOM)是一种强大的无监督数据可视化工具,它通过降维技术,在较低(通常二维)的空间中有效地展示高维数据集的内在结构和特征。在本文中,我们将详细探讨如何帮助客户利用R语言实现SOM,以可视化银行客户的信用人口属性数据(点击文末“阅读原文”获取完整代码数据)。 相关视频 ...
R语言软件对房屋价格预测:回归、LASSO、决策树、随机森林、GBM、神经网络和SVM可视化|数据分享
在房地产市场中,准确地预测房屋价格是至关重要的。过去几十年来,随着数据科学和机器学习的快速发展,各种预测模型被广泛应用于房屋价格预测中。而R语言作为一种强大的数据分析和统计建模工具,被越来越多的研究者和从业者选择用于房屋价格预测(点击文末“阅读原文”获取完整代码数据)。 相关视频 ...
【视频】R语言用线性回归预测共享单车的需求和可视化|数据分享
全文链接:https://tecdat.cn/?p=33350 分析师:Shuli Wang 自行车共享系统是新一代的传统自行车租赁,从会员,租赁到归还的整个过程已经自动化。通过这些系统,用户可以轻松地从特定位置租用自行车,然后在另一个位置返回(点击文末“阅读原文”获取完整代码数据)。 目前,全球约有500多个自行车共享计划,其中包括500多万辆自行车...

R语言可视化探索BRFSS数据并逻辑回归Logistic回归预测中风
行为风险因素监视系统(BRFSS)是美国的年度电话调查。BRFSS旨在识别成年人口中的危险因素并报告新兴趋势(点击文末“阅读原文”获取完整代码数据)。 加载包 library(ggplot2) ...
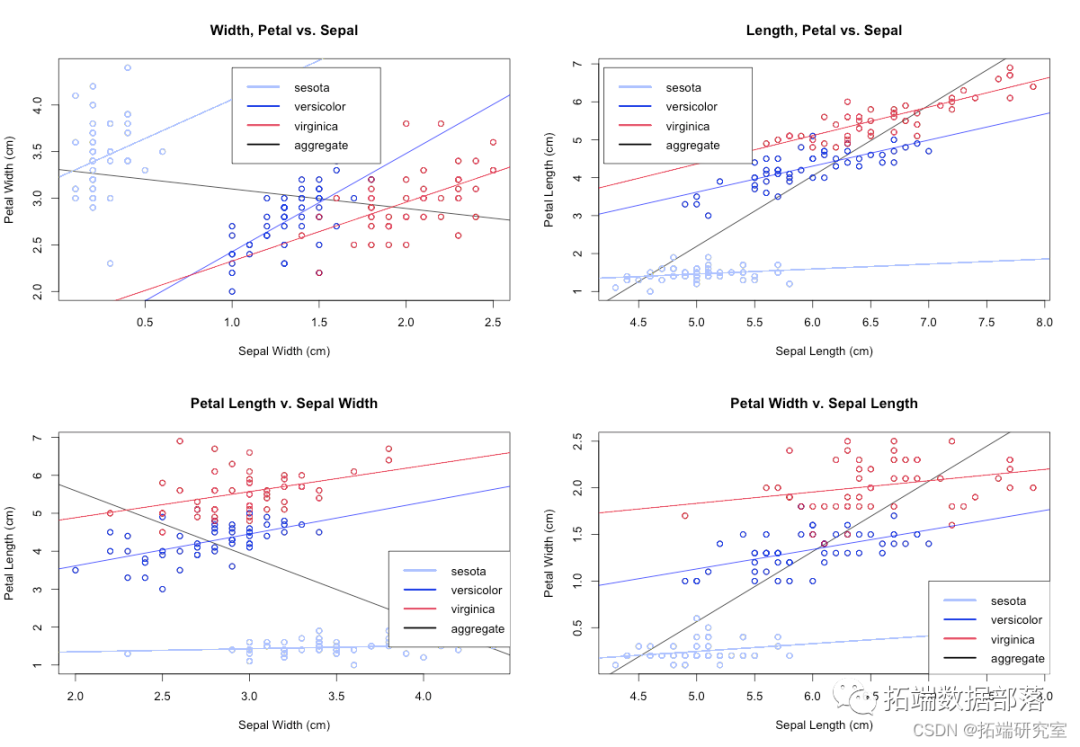
R语言使用逻辑回归Logistic、单因素方差分析anova、异常点分析和可视化分类iris鸢尾花数据集|数据分享
全文链接:http://tecdat.cn/?p=27650 摘要 本文将探讨 Fisher 和 Anderson 鸢尾花数据集(查看文末了解数据获取方式)中呈现的三个变量之间的关系,特别是virginica 和 versicolor 级别的因变量变量物种对预测变量花瓣长...
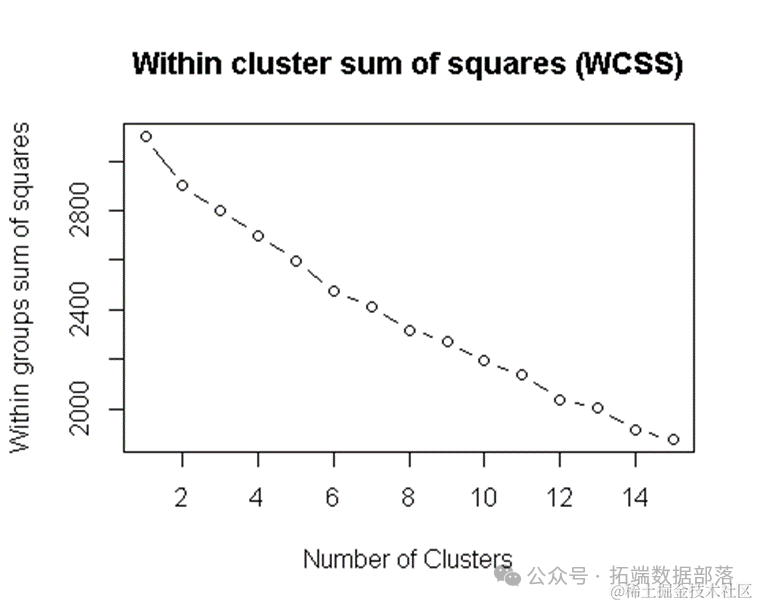
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福指数可视化|数据分享(下)
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福指数可视化|数据分享(上):https://developer.aliyun.com/article/1491650 欧氏距离 我们将使用欧几里得距离找到彼此最相似的国家,并将它们分组在一起。 ...
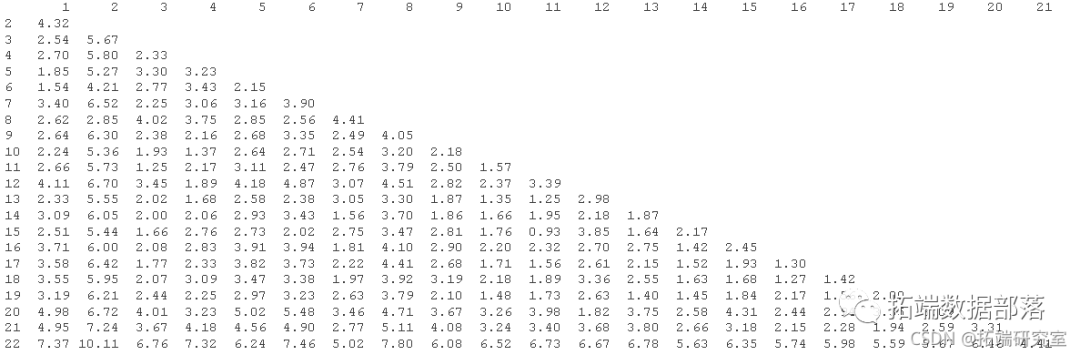
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福指数可视化|数据分享(上)
原文链接:http://tecdat.cn/?p=24198 聚类是将总体或数据点划分为多个组的任务,以使同一组中的数据点与同一组中的其他数据点更相似,而与其他组中的数据点不相似。它基本上是基于它们之间的相似性和相异性的对象的集合。 在本项目中,我将使用世界幸福报告中的数据(查看文末了解数据获取方式)来探索亚洲22个国家或地区,并通过查看每个国家的阶梯得分,社会支持,健...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。