
R语言随机波动模型SV:马尔可夫蒙特卡罗法MCMC、正则化广义矩估计和准最大似然估计上证指数收益时间序列
全文链接:http://tecdat.cn/?p=31162 最近我们被客户要求撰写关于SV模型的研究报告,包括一些图形和统计输出(点击文末“阅读原文”获取完整代码数据)。 本文做SV模型,选取马尔可夫蒙特卡罗法(MCMC)、正则化广义矩估计法和准最大似然估计法估计。 模拟SV模型的估计方法: ...

R语言弹性网络Elastic Net正则化惩罚回归模型交叉验证可视化
原文链接:http://tecdat.cn/?p=26158 弹性网络正则化同时应用 L1 范数和 L2 范数正则化来惩罚回归模型中的系数。为了在 R 中应用弹性网络正则化。在 LASSO回归中,我们为 alpha 参数设置一个 '1' 值,并且在 岭回归中,我们将 '0' 值设置为其 alpha 参数。弹性网络在 0 到 1 的范围内搜索最佳 alpha 参数。在这篇文章中,我们将学习...
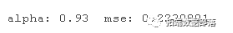
R语言梯度提升机 GBM、支持向量机SVM、正则判别分析RDA模型训练、参数调优化和性能比较可视化分析声纳数据
原文链接:http://tecdat.cn/?p=24354 本文介绍简化模型构建和评估过程。 caret包的train 函数可用于 使用重采样评估模型调整参数对性能的影响 在这些参数中选择“最佳”模型 从训练集估计模型性能 首先,必须选择特定的模型。 调整模型的第一步是选择一组要评估的参数。例如,如果拟合偏最小二...
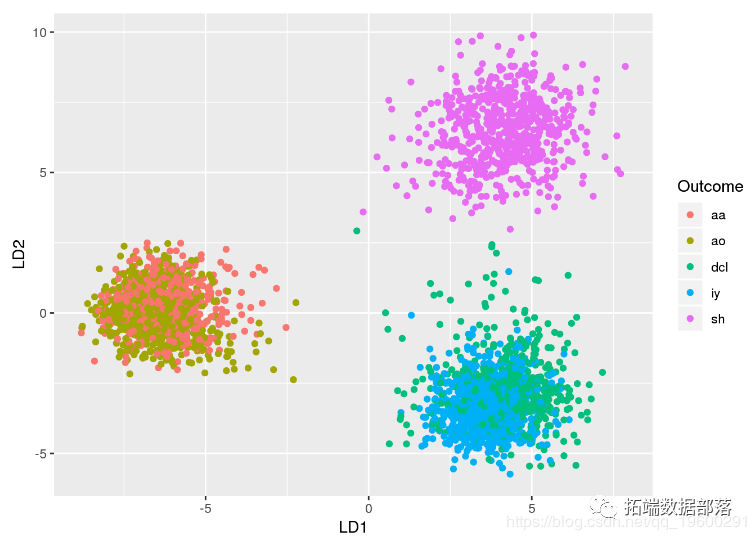
R语言线性判别分析(LDA),二次判别分析(QDA)和正则判别分析(RDA)
判别分析包括可用于分类和降维的方法。线性判别分析(LDA)特别受欢迎,因为它既是分类器又是降维技术。二次判别分析(QDA)是LDA的变体,允许数据的非线性分离。最后,正则化判别分析(RDA)是LDA和QDA之间的折衷。 本文主要关注LDA,并探讨其在理论和实践中作为分类和可视化技术的用途。由于QDA和RDA是相关技术,我不久将描述它们的主要属性以及如何在R中使用它们。 ...
预测分析:R语言实现2.7 正则化
2.7 正则化 变量选择是一个重要的过程,因为它试图通过去除与输出无关的变量,让模型解释更简单、训练更容易,并且没有虚假的关联。这是处理过拟合问题的一种可能的方法。总体而言,我们并不期望一个模型能完全拟合训练数据。实际上,过拟合问题通常意味着,如果过分拟合训练数据,对我们在未知数据上的预测模型精确度反而是有害的。在关于正则化(regularization)的这一节,我们要学习一种减少变量数以处.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。