
分布式可视化MapReduce编程模型
可视化MapReduce模型在MapReduce模型的基础上,新增了可视化可运维的能力。您无需修改后端代码,只需在SchedulerX控制台将分布式模型改为可视化MapReduce,即可新增一个子任务列表页面,并且可以查看每个子任务的详情、结果和日志,同时支持每个子任务级别的重跑。
分布式可视化MapReduce编程模型
可视化MapReduce模型在MapReduce模型的基础上,新增了可视化可运维的能力。您无需修改后端代码,只需在SchedulerX控制台将分布式模型改为可视化MapReduce,即可新增一个子任务列表页面,并且可以查看每个子任务的详情、结果和日志,同时支持每个子任务级别的重跑。
分布式可视化MapReduce编程模型
可视化MapReduce模型在MapReduce模型的基础上,新增了可视化可运维的能力。您无需修改后端代码,只需在SchedulerX控制台将分布式模型改为可视化MapReduce,即可新增一个子任务列表页面,并且可以查看每个子任务的详情、结果和日志,同时支持每个子任务级别的重跑。
Hadoop【基础知识 02】【分布式计算框架MapReduce核心概念+编程模型+combiner&partitioner+词频统计案例解析与进阶+作业的生命周期】(图片来源于网络)
1. 概述 同 HDFS 一样,Hadoop MapReduce 也采用了 Master/Slave(M/S)架构,具体如图所示。它主要由以下几个组件组成:Client、JobTracker、TaskTracker 和 Task。 下面分别对这几个组件进行介绍。 Client 我们将编写的 MapReduce 程序通过 Client 提交到 JobTracker 端;同时也可通过 Clie...

MapReduce编程例子之Combiner与Partitioner
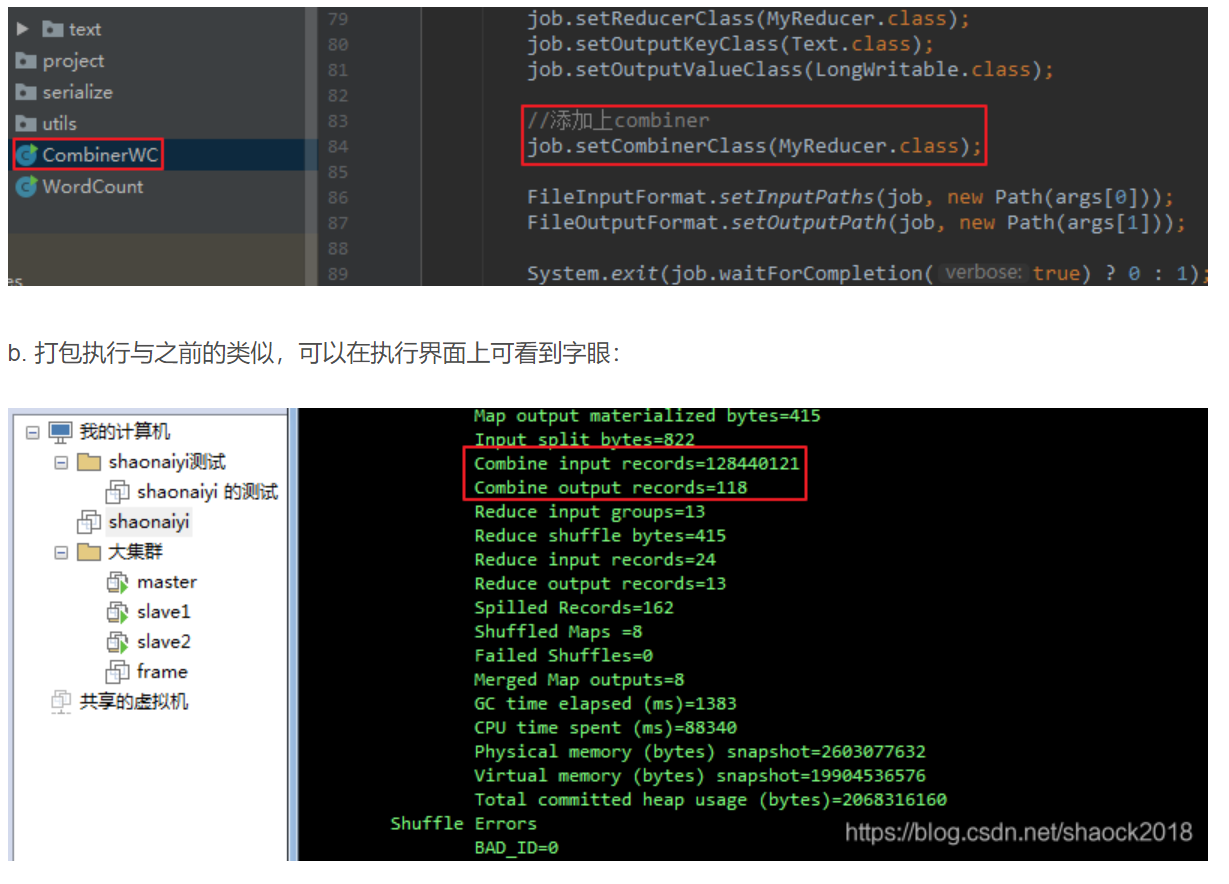
0x00 教程内容本教程是在“MapReduce入门例子之单词计数”上做的升级,请查阅此教程。包括了实现Combiner与Partitioner编程,都是一些编程技巧。0x01 Combiner讲解1. 优势a. 其实就是本地的reducer,在本地先聚合一次b. 可以减少Map Tasks输出的数据量以及数据网络的传输量2. 使用场景a. 适用于求和、次数等的加载b. 求平均数等的计算并不合适....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce大规模
- mapreduce数据
- mapreduce列表
- mapreduce集群
- mapreduce聚合
- mapreduce可视化
- mapreduce driver
- mapreduce序列化
- mapreduce日志
- mapreduce代码
- mapreduce hadoop
- mapreduce spark
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务
- mapreduce原理