
使用DeepNCCL加速模型的分布式训练或推理性能
DeepNCCL是阿里云神龙异构产品开发的用于多GPU互联的AI通信加速库,能够无感地加速基于NCCL进行通信算子调用的分布式训练或多卡推理等任务。开发人员可以根据实际业务情况,在不同的GPU云服务器上安装DeepNCCL通信库,以加速分布式训练或推理性能。本文主要介绍在Ubuntu或CentOS操作系统的GPU实例上安装和使用DeepNCCL的操作方法。
GPU 加速与 PyTorch:最大化硬件性能提升训练速度
摘要 GPU(图形处理单元)因其并行计算能力而成为深度学习领域的重要组成部分。本文将介绍如何利用PyTorch来高效地利用GPU进行深度学习模型的训练,从而最大化训练速度。我们将讨论如何配置环境、选择合适的硬件、编写高效的代码以及利用高级特性来提高性能。 1. 引言 深度学习模型的训练过程通常需要大量的计算资源。GPU因其高度并行化的架构而成为加速这些计...
安装和使用Deepytorch Training提升训练加速能力
Deepytorch Training是阿里云自研的AI加速器,面向传统AI和生成式AI场景,在模型训练过程中,可提供显著的训练加速能力。本文主要介绍安装并使用Deepytorch Training的操作方法。
Deepytorch Training(训练加速)介绍、优势及特性
Deepytorch Training是阿里云自研的AI训练加速器,为传统AI和生成式AI场景提供训练加速功能。本文主要介绍Deepytorch Training在训练加速上的概念、优势及特性等。
【多GPU炼丹-绝对有用】PyTorch多GPU并行训练:深度解析与实战代码指南
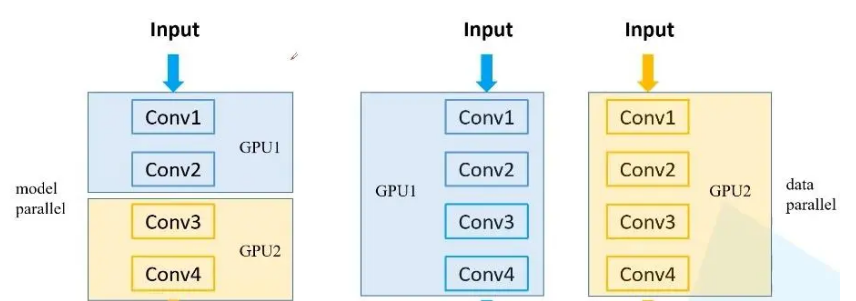
a. 数据拆分,模型不拆分 b. 数据不拆分,模型拆分 c. 数据拆分,模型拆分 在深度学习的炼丹之路上,多GPU的使用如同助燃剂,能够极大地加速模型的训练和测试。根据不同的GPU数量和内存配置,我们可以选择多种策略来充分利用这些资源。今天,我们将围绕“多GPU炼丹”这一主题,深度解析PyTorch多GPU并行训练的技巧,并为大家带来实战代码指南。在这个过程中,我们将不断探讨和展示如何...
【AMP实操】解放你的GPU运行内存!在pytorch中使用自动混合精度训练
前言 自动混合精度(Automatic Mixed Precision,简称AMP)是一种深度学习加速技术,它通过在训练过程中自动选择合适的数值类型(如半精度浮点数和单精度浮点数)来加速计算,并减少内存占用,从而提高训练速度和模型性能。 精度 半精度 半精度浮点数(Half-Precision Floating Point)是一种浮点数数据类型,也被称为1...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
GPU云服务器您可能感兴趣
- GPU云服务器device
- GPU云服务器运算
- GPU云服务器部署
- GPU云服务器模型
- GPU云服务器优惠
- GPU云服务器异构
- GPU云服务器实践
- GPU云服务器分布式
- GPU云服务器环境
- GPU云服务器集群
- GPU云服务器阿里云
- GPU云服务器服务器
- GPU云服务器实例
- GPU云服务器modelscope
- GPU云服务器cpu
- GPU云服务器函数计算
- GPU云服务器nvidia
- GPU云服务器ai
- GPU云服务器性能
- GPU云服务器计算
- GPU云服务器版本
- GPU云服务器安装
- GPU云服务器推理
- GPU云服务器函数计算fc
- GPU云服务器配置
- GPU云服务器资源
- GPU云服务器深度学习
- GPU云服务器购买
- GPU云服务器价格
- GPU云服务器参数

