
在e-mapreduce跑spark streaming,计划1分钟打印一条日志发现没有打印
在e-mapreduce跑spark streaming,1分钟打印一条日志发现没有打印。
使用E-MapReduce,spark中读取oss文件
运行spark报如下错误:注:已配accessKeyId,accessKeySecret,endpoint
通过Job Committer保证Mapreduce/Spark任务数据一致性
作者:李呈祥,花名司麟,阿里云智能EMR团队高级技术专家,Apache Hive Committer, Apache Flink Committer,目前主要专注于EMR产品中开源计算引擎的优化工作。 并发地向目标存储系统写数据是分布式任务的一个天然特性,通过在节点/进程/线程等级别的并发写数据,充分利用集群的磁盘和网络带宽,实现高容量吞吐。并发写数据的一个主要需要解决的问题就是如何保证数据一.....
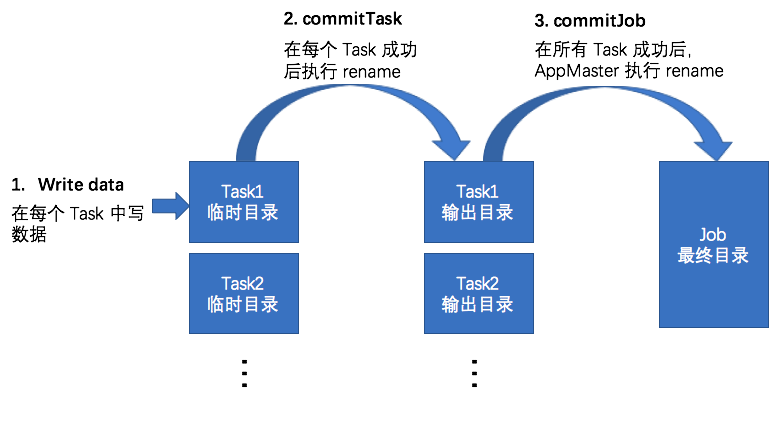
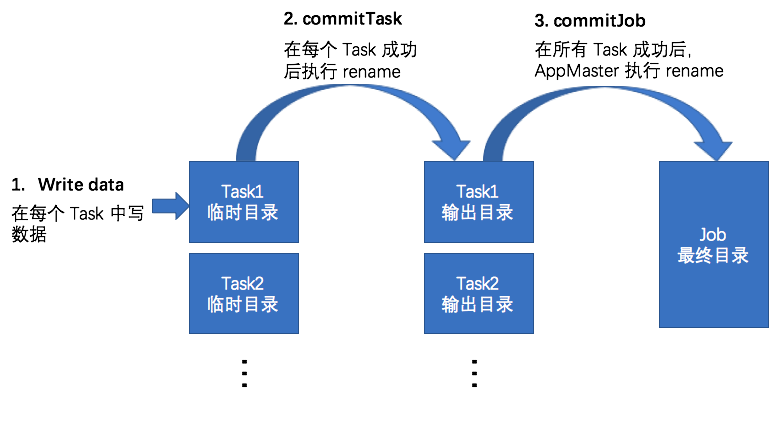
通过Job Committer保证Mapreduce/Spark任务数据一致性
并发地向目标存储系统写数据是分布式任务的一个天然特性,通过在节点/进程/线程等级别的并发写数据,充分利用集群的磁盘和网络带宽,实现高容量吞吐。并发写数据的一个主要需要解决的问题就是如何保证数据一致性的问题,具体来说,需要解决下面列出的各个问题: 在分布式任务写数据的过程中,如何保证中间数据对外不可见。 在分布式任务正常完成后,保证所有的结果数据同时对外可见。 在分布式任务失败时,所有结果数据对.....
Hadoop、MapReduce、YARN和Spark的区别与联系
Hadoop、MapReduce、YARN和Spark的区别与联系 转载:http://www.aichengxu.com/view/1103036 2015-03-17 16:37 本站整理 浏览(454) (1) Hadoop 1.0 第一代Hadoop,由分布式存储系统HDFS和分布式计算框架 MapReduce组成,其中,HDFS由一个NameNode和多个Da...
MapReduce Shuffle原理 与 Spark Shuffle原理
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。 为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数...
Cloudera CTO:取代MapReduce 未来会加大Spark等框架投入
MapReduce的高延迟已经成为Hadoop发展的瓶颈,为当前的MapReduce寻找性能更高的替代品已成为Hadoop社区的一个共识。 MapReduce 有关MapReduce框架,最早要追溯到Google,Google将这个框架与灵活、可扩展性存储结合到一起,用以解决各类数据处理和分析任务。后来Doug Cutting和Mike Cafarella在2005年联合创立了Apache Ha....
阿里云E-MapReduce Spark SQL 作业配置
.注意:Spark SQL 提交作业的模式默认是 yarn-client` 模式。 2.进入阿里云E-MapReduce控制台作业列表。 3.单击该页右上角的创建作业,进入创建作业页面。 4.填写作业名称。 5.选择 Spark SQL 作业类型,表示创建的作业是一个 Spark SQL 作业。Spark SQL 作业在 E-MapReduce 后台使用以下的方式提交: spark-sql [o....
Hive、MapReduce、Spark分布式生成唯一数值型ID
在实际业务场景下,经常会遇到在Hive、MapReduce、Spark中需要生成唯一的数值型ID。 一般常用的做法有: MapReduce中使用1个Reduce来生成; Hive中使用row_number分析函数来生成,其实也是1个Reduce; 借助HBase或Redis或Zookeeper等其它框架的计数器来生成; 数据量不大的情况下,可以直接使用1和2方法来生成,但如果数据量巨大,1个Re....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark任务管理
- apache spark训练
- apache spark特征
- apache spark实战
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark应用
- apache spark yarn
- apache spark技术
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注