
【Python机器学习】实验11 支持向量机2
1.4 可视化分析#绘制图片 plt.figure(figsize=(12,4)) plt.subplot(1,2,1) plt.scatter(data1["X1"],data1["X2"],marker="s",c=data1["SV1 decision function"],cmap='seismic') plt.title("SVC1") plt.subplot(1,2,2) plt.s....
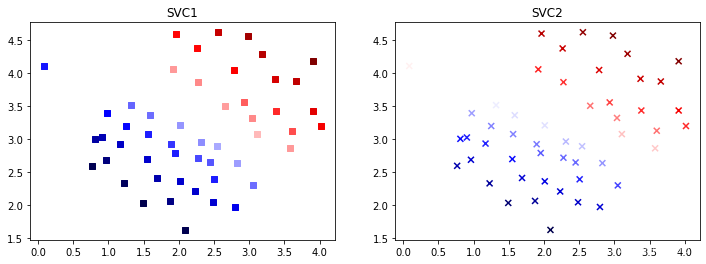
【Python机器学习】实验11 支持向量机1
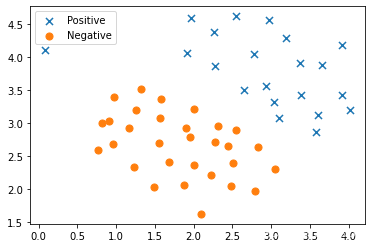
支持向量机在本练习中,我们将使用支持向量机(SVM)来构建垃圾邮件分类器。 我们将从一些简单的2D数据集开始使用SVM来查看它们的工作原理。 然后,我们将对一组原始电子邮件进行一些预处理工作,并使用SVM在处理的电子邮件上构建分类器,以确定它们是否为垃圾邮件。我们要做的第一件事是看一个简单的二维数据集,看看线性SVM如何对数据集进行不同的C值(类似于线性/逻辑回归中的正则化项)。实例1 线性可分....
【Python机器学习】实验10 随机森林和集成学习
随机森林和集成学习import warnings warnings.filterwarnings("ignore") import pandas as pd from sklearn.model_selection import train_test_split 1. 生成数据生成12000行的数据,训练集和测试集按照3:1划分#生成12000个,维度为10维,类别为2的数据 from sk...
【Python机器学习】实验08 K-means无监督聚类 2
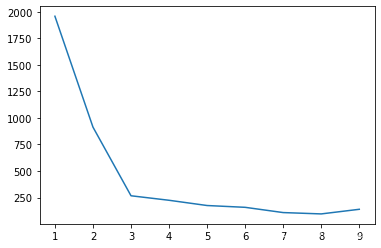
8 使用“肘部法则”选取k值def selecte_K(X,iter_num): dist_arry=[] for k in range(1,10): centroids,idx=k_means(data.values,k,iter_num) dist_arry.append((k,metric_square(X,idx,centroids,k))...
【Python机器学习】实验09 决策树2
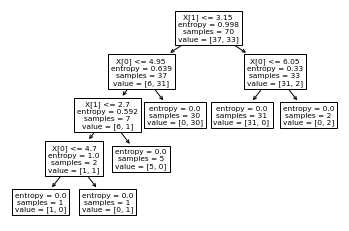
决策树分类from sklearn.tree import DecisionTreeClassifier from sklearn.tree import export_graphviz import graphviz #1 导入相关包 from sklearn import tree #2 构建一个决策树分类器模型 clf = DecisionTreeClassifier(criterion=....
【Python机器学习】实验09 决策树1
决策树1.分类决策树模型是表示基于特征对实例进行分类的树形结构。决策树可以转换成一个if-then规则的集合,也可以看作是定义在特征空间划分上的类的条件概率分布。2.决策树学习旨在构建一个与训练数据拟合很好,并且复杂度小的决策树。因为从可能的决策树中直接选取最优决策树是NP完全问题。现实中采用启发式方法学习次优的决策树。决策树学习算法包括3部分:特征选择、树的生成和树的剪枝。常用的算法有ID3、....

【Python机器学习】实验08 K-means无监督聚类 1
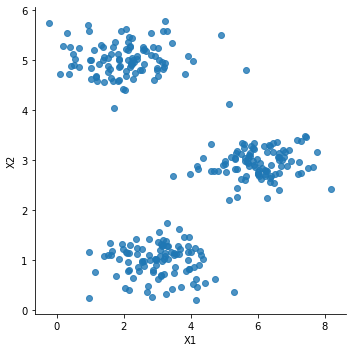
聚类在本练习中,我们将实现K-means聚类K-means 聚类我们将实施和应用K-means到一个简单的二维数据集,以获得一些直观的工作原理。 K-means是一个迭代的,无监督的聚类算法,将类似的实例组合成簇。 该算法通过猜测每个簇的初始聚类中心开始,然后重复将实例分配给最近的簇,并重新计算该簇的聚类中心。 我们要实现的第一部分是找到数据中每个实例最接近的聚类中心的函数。1 准备数据无监督学....
【Python机器学习】实验07 KNN最近邻算法2
试试Scikit-learnsklearn.neighbors.KNeighborsClassifiern_neighbors: 临近点个数,即k的个数,默认是5p: 距离度量,默认algorithm: 近邻算法,可选{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}weights: 确定近邻的权重n_neighbors : int,optional(defaul....
【Python机器学习】实验07 KNN最近邻算法1
KNN算法1.k kk近邻法是基本且简单的分类与回归方法。k kk近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的k kk个最近邻训练实例点,然后利用这k kk个训练实例点的类的多数来预测输入实例点的类。2.k kk近邻模型对应于基于训练数据集对特征空间的一个划分。k kk近邻法中,当训练集、距离度量、k kk值及分类决策规则确定后,其结果唯一确定,没有近似,他没有学习参....
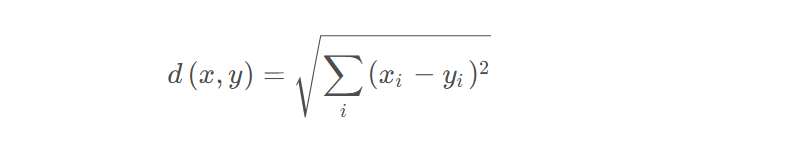
【Python机器学习】实验06 贝叶斯推理3
2 数据读取–训练集和测试集的划分#划分数据为训练数据和测试数据 from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=0) X_train.shape,X_test.shape,y_tra....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
人工智能平台 PAI您可能感兴趣
- 人工智能平台 PAI图像
- 人工智能平台 PAI分类
- 人工智能平台 PAI优化
- 人工智能平台 PAI应用
- 人工智能平台 PAI模型
- 人工智能平台 PAI游戏
- 人工智能平台 PAI人工智能
- 人工智能平台 PAI rag
- 人工智能平台 PAI供应链
- 人工智能平台 PAI pai-chatlearn
- 人工智能平台 PAI pai
- 人工智能平台 PAI机器学习
- 人工智能平台 PAI算法
- 人工智能平台 PAI数据
- 人工智能平台 PAI平台
- 人工智能平台 PAI训练
- 人工智能平台 PAI实战
- 人工智能平台 PAI构建
- 人工智能平台 PAI ai
- 人工智能平台 PAI入门
- 人工智能平台 PAI实践
- 人工智能平台 PAI深度学习
- 人工智能平台 PAI方法
- 人工智能平台 PAI特征
- 人工智能平台 PAI阿里云
- 人工智能平台 PAI部署
- 人工智能平台 PAI代码
- 人工智能平台 PAI技术
- 人工智能平台 PAI学习
- 人工智能平台 PAI报错

阿里云机器学习平台PAI
阿里云机器学习PAI(Platform of Artificial Intelligence)面向企业及开发者,提供轻量化、高性价比的云原生机器学习平台,涵盖PAI-iTAG智能标注平台、PAI-Designer(原Studio)可视化建模平台、PAI-DSW云原生交互式建模平台、PAI-DLC云原生AI基础平台、PAI-EAS云原生弹性推理服务平台,支持千亿特征、万亿样本规模加速训练,百余落地场景,全面提升工程效率。
+关注
