
日志相似度聚类、词频聚类和模板匹配算法说明
日志服务异常智能分析应用提供文本分析功能,用于对日志中的文本日志进行智能化、自动化的分析,提供全局的统计分析结果。文本分析功能通过日志模板发现和日志模板匹配两个子任务,实现对于日志数据的监控和统计。您可以根据待分析的日志数据的特点,选择不同的任务和算法。
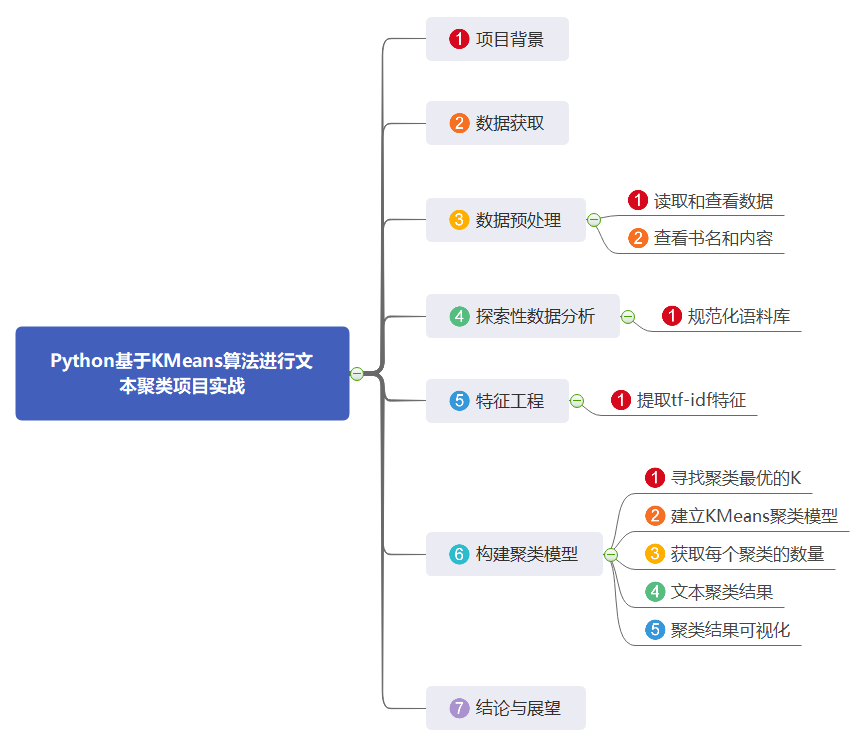
Python基于KMeans算法进行文本聚类项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。 ...
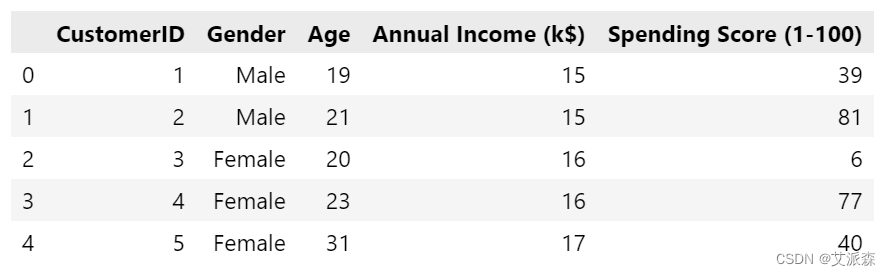
数据挖掘实战:基于KMeans算法对超市客户进行聚类分群
一、研究背景 超市作为零售业的主要形式之一,在现代都市生活中扮演着重要角色。随着社会经济的发展和消费者需求的变化,超市经营者越来越意识到了客户细分的重要性。不同的客户群体有着不同的购物习惯、消费行为和偏好,了解并满足不同客户群体的需求,可以帮助超市提供更加个性化的服务和商品推荐,从而提升客户的满意度和忠诚度,促进超市的经营发展。 ....
kmeans算法入门案例以聚类中心数的确定
kmeans案例分析kmeans具体流程第一步:指定聚类类数k(文章后面会讲解k的选择方法)第二步:选定初始化聚类中心。随机或指定k个对象,作为初始化聚类中心第三步:得到初始化聚类结果。计算每个对象到k个聚类中心的距离,把每个对象分配给离它最近的聚类中心所代表的类别中,全部分配完毕即得到初始化聚类结果,聚类中心连同分配给它的对象作为一类第四步:重新计算聚类中心。得到初始化聚类结果后,重新计算每类....

m基于kmeans和Cmeans算法的数据聚类仿真分析
1.算法描述 K-means聚类算法是硬聚类算法,是典型的基于原型的目标函数聚类分析算法点到原型——簇中心的某种距离和作为优化的目标函数,采用函数求极值的方法得到迭代运算的调整规则。K-means聚类算法以欧氏距离作为相异性测度它是求对应某一初始聚类中心向量 最优分类,使得评价指标E值最小。K-means聚类算法采用误差平方和准则函数作为聚类准则函数,误差平方和准则函数定义为: 分析误差...

基于kmeans算法的数据聚类matlab仿真
1.算法描述 聚类算法也许是机器学习中“新算法”出现最多、最快的领域,一个重要的原因是聚类不存在客观标准,给定数据集总能从某个角度找到以往算法未覆盖的某种标准从而设计出新算法。Kmeans算法十分简单易懂而且非常有效,但是合理的确定K值和K个初始类簇中心点对于聚类效果的好坏有很大的影响。众多的论文基于此都提出了各自行之有效的解决方案,新的改进算法仍然不断被提出,此类文章大家可以在Web Of...
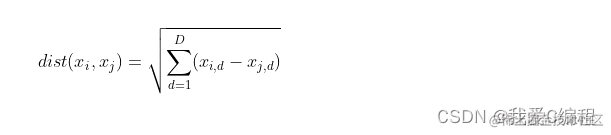
目标检测的Tricks | 【Trick13】使用kmeans与遗传算法聚类anchor
1. kmeans聚类中心参考代码:plot_kmeans.pyimport numpy as np from matplotlib import pyplot as plt np.random.seed(0) colors = np.array(['blue', 'black']) def plot_clusters(data, cls, clusters, title=""): # ...
使用ST_ClusterKMeans返回基于二维K均值算法生成的聚类结果数量(PostgreSQL引擎)
返回每个Geometry对象基于二维K均值算法生成的聚类结果数量。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

