
使用云工作流和函数计算构建ETL离线数据处理系统实现对数据的自动化处理
您可以使用云工作流和函数计算轻松构建ETL离线数据处理系统,实现更灵活、成本更低的数据处理解决方案。您无需管理底层服务器资源,从而更加聚焦于业务逻辑本身。
DataWorks中EMR Serverless Spark版本的用户画像分析的加工数据阶段
本文为您介绍如何用Spark SQL创建外部用户信息表ods_user_info_d_spark以及日志信息表ods_raw_log_d_spark访问存储在私有OSS中的用户与日志数据,通过DataWorks的EMR Spark SQL节点进行加工得到目标用户画像数据,阅读本文后,您可以了解如何通过Spark SQL来计算和分析已同步的数据,完成数仓简单数据加工场景。



一键启停SAE应用监控并查看监控数据
SAE集成了ARMS的多种监控能力,在开启并接入ARMS高级监控后,可以帮助您快速定位出错接口和慢接口、检测内存泄漏和发现系统瓶颈,从而大幅提升线上问题诊断的效率。本文介绍如何在SAE一键启停应用监控并查看监控数据。
查询外部数据
本文介绍如何通过External Catalog查询外部数据。External Catalog方便您轻松访问并查询存储在各类外部源的数据,无需创建外部表。
实时计算 Flink版产品使用问题之使用cdas语法同步mysql数据到sr serverless是否支持动态加表
问题一:Flink 将所有的 TaskManager 都走这个 JobManager 来管理吗? 最近我们有从 Flink On Yarn 转到 K8S 的需求,我自己做了下测试,直接将之前的 Thin Jar 发布到 container,然后挂载通用 NAS 里面的Dependency ,好像也完全可以,几乎0迁移成本。但是有个小小的问题就是,我如何确定 JobManager 的位置呢...
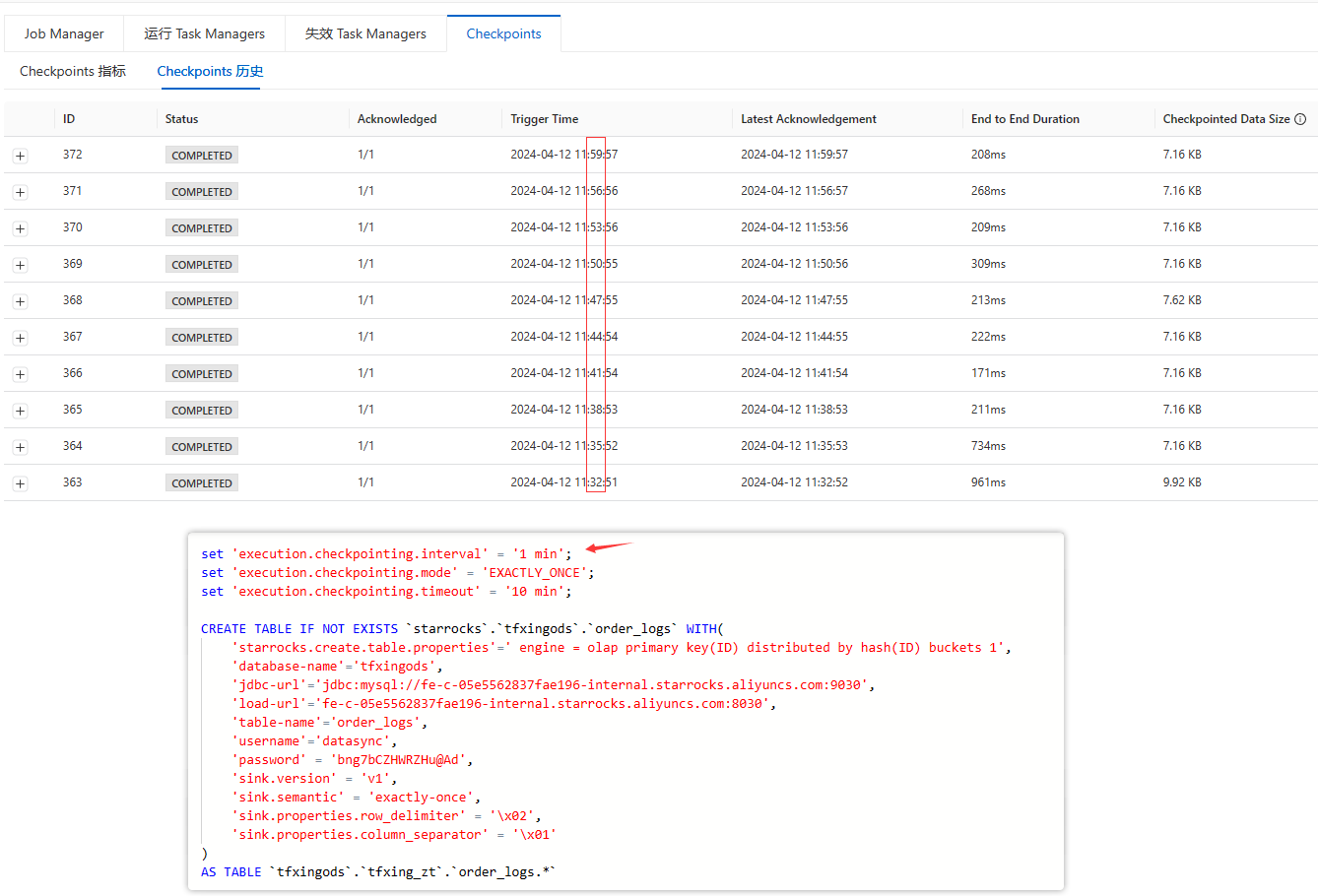
Flink使用cdas语法同步mysql数据到sr serverless支持动态加表吗?
Flink使用cdas语法同步mysql数据到sr serverless支持动态加表吗?
flink CDAS同步数据至SR serverless ,只把表结构同步过去,就报错,如何解决?
flink CDAS同步数据至SR serverless ,只把表结构同步过去,同步数据就报错,如何解决?Caused by: com.starrocks.streamload.shade.org.apache.http.ProtocolException: The server failed to respond with a valid HTTP response 作业链接:https://....
数据之势丨云原生数据库,走向Serverless与AI驱动的一站式数据平台
《云栖战略参考》由阿里云与钛媒体联合策划,呈现云计算与人工智能领域的最新技术战略观点与业务实践探索,希望这些内容能让您有所启发。 2005年,商业数据库时代启幕,至2009年起开源数据库潮流涌动,阿里巴巴率先提出“去IOE”,用分布式架构替代传统商业数据库。2017年,阿里云自研了第一款云原生数据库PolarDB。从AliSQL到RDS,再到自研PolarDB,阿里云瑶池数据库的演进历程犹如...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
