
数据湖技术:Hadoop与Spark在大数据处理中的协同作用
数据湖技术:Hadoop与Spark在大数据处理中的协同作用 在大数据时代,数据湖技术以其灵活性和成本效益成为了企业存储和分析大规模异构数据的首选。Hadoop和Spark作为数据湖技术中的两个核心组件,它们在大数据处理中的协同作用至关重要。本文将探讨Hadoop与Spark的最佳实践,以及如何在实际应用中发挥它们的协同效应。 Hadoop...
数据湖技术:Hadoop与Spark在大数据处理中的协同作用
随着大数据技术的不断发展,数据湖作为一种集中式存储和处理海量数据的架构,越来越受到企业的青睐。Hadoop和Spark作为数据湖技术的两大核心组件,在大数据处理中发挥着不可替代的作用。本文将通过最佳实践的形式,详细探讨Hadoop与Spark在大数据处理中的协同作用,并提供具体的示例代码。 Hadoop,作为一个...
大数据技术:Hadoop与Spark的对比
一、引言 随着数据量的爆炸性增长,大数据技术成为了处理和分析这些海量数据的关键。Hadoop和Spark作为当前最流行的大数据处理框架,各自具有独特的优势和适用场景。本文将对Hadoop和Spark进行详细的对比,帮助读者更好地理解两者的异同,以便在实际应用中做出明智的选择。 二、Hadoop概述 Hadoop是一个由Apache基金会开发...
探索大数据技术:Hadoop与Spark的奥秘之旅
在当今这个信息爆炸的时代,大数据已经成为了推动社会进步和企业发展的重要力量。为了更好地利用这些海量的数据资源,大数据技术如Hadoop和Spark应运而生,为我们提供了强大的数据处理和分析能力。本文将带领大家深入探索Hadoop和Spark的技术奥秘,解析它们的工作原理、应用场景以及未来发展趋势。 一、Hadoop:大数据处理...
大数据技术与Python:结合Spark和Hadoop进行分布式计算
随着互联网的普及和技术的飞速发展,大数据已经成为当今社会的重要资源。大数据技术是指从海量数据中提取有价值信息的技术,它包括数据采集、存储、处理、分析和挖掘等多个环节。Python作为一种功能强大、简单易学的编程语言,在数据处理和分析领域具有广泛的应用。本文将介绍如何使用Python结合Spark和Hadoop进行分布式计算,以应对大数据挑战...
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
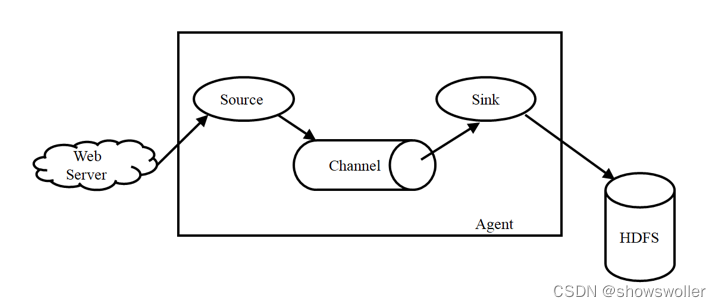
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:完成对日志数据的收集,分成transtion 和 event 打入到channel之中。2)Cha....
【大数据技术Hadoop+Spark】Spark SQL、DataFrame、Dataset的讲解及操作演示(图文解释)
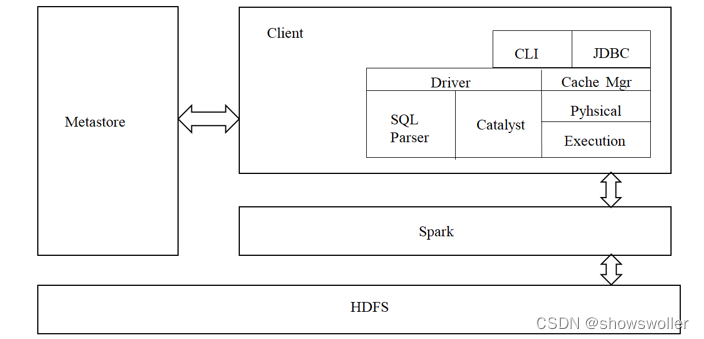
一、Spark SQL简介park SQL是spark的一个模块,主要用于进行结构化数据的SQL查询引擎,开发人员能够通过使用SQL语句,实现对结构化数据的处理,开发人员可以不了解Scala语言和Spark常用API,通过spark SQL,可以使用Spark框架提供的强大的数据分析能力。spark SQL前身为Shark。Shark是Spark上的数据仓库,最初设计成与Hive兼容,但是该项目....
【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、RDD的创建Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。1、从文件系统加载数据创建RDD从运行结果反馈的信息可以看出,wordfile是一个String类型的RDD,或者以后可以简单....
【大数据技术Hadoop+Spark】Spark RDD设计、运行原理、运行流程、容错机制讲解(图文解释)
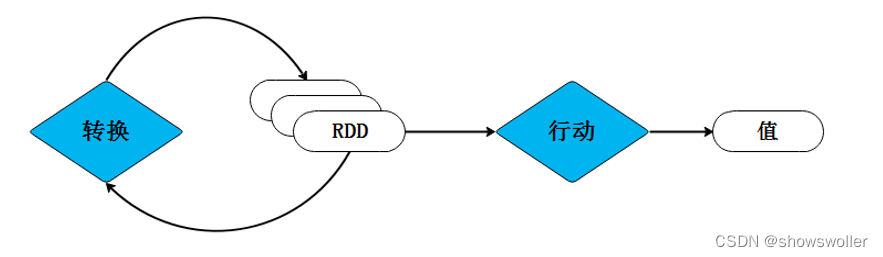
一、RDD的概念RDD(Resilient Distributed Dataset),即弹性分布式数据集,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并且还能控制数据的分区。不同RDD之间可以通过转换操作形成依赖关系实现管道化,从而避免了中间结果的I/O操作,提高数据处理的速度和性能。一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成....
【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
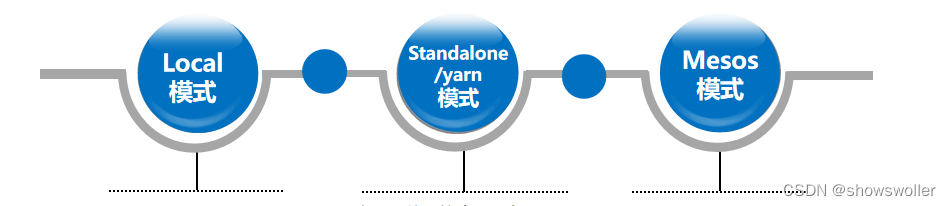
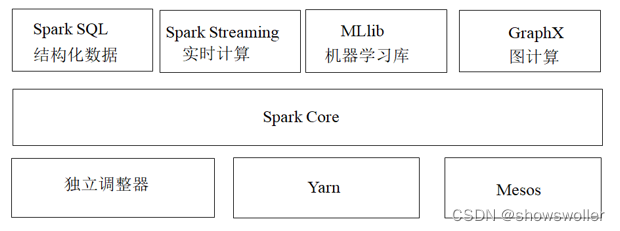
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop您可能感兴趣
- hadoop开发环境
- hadoop hbase
- hadoop集群
- hadoop数据处理
- hadoop数据分析
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop大数据
- hadoop集群管理
- hadoop hdfs
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop分布式
- hadoop数据
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作
