
分布式爬虫去重:Python + Redis实现高效URL去重
引言在互联网数据采集(爬虫)过程中,URL去重是一个关键问题。如果不对URL进行去重,爬虫可能会重复抓取相同页面,导致资源浪费、数据冗余,甚至触发目标网站的反爬机制。对于单机爬虫,可以使用Python内置的set()或dict进行去重,但在分布式爬虫环境下,多个爬虫节点同...
Python爬虫异常处理:自动跳过无效URL
爬虫在运行过程中常常会遇到各种异常情况,其中无效URL的出现是较为常见的问题之一。无效URL可能导致爬虫程序崩溃或陷入无限等待状态,严重影响爬虫的稳定性和效率。因此,掌握如何在Python爬虫中自动跳过无效URL的异常处理技巧,对于提升爬虫的健壮性和可靠性至关重要。 一、无效URL的常见类型 在爬虫运行过程中,无效URL主要分为以下几种类型: (一)格式错误的URL ...

小说爬虫-03 爬取章节的详细内容并保存 将章节URL推送至RabbitMQ Scrapy消费MQ 对数据进行爬取后写入SQLite
代码仓库 代码我已经上传到 Github,大家需要的可以顺手点个 Star! https://github.com/turbo-duck/biquge_fiction_spider 背景介绍上一节已经拿到了 小说的详细内容 和 章节的列表 接下来,将章节的列表使用脚本从...
Java爬虫开发:Jsoup库在图片URL提取中的实战应用
在当今的互联网时代,数据的获取和处理变得尤为重要。对于网站内容的自动化抓取,爬虫技术扮演着不可或缺的角色。Java作为一种广泛使用的编程语言,拥有丰富的库支持网络爬虫的开发。其中,Jsoup库以其简洁、高效的特点,成为处理HTML内容和提取数据的优选工具。本文将详细介绍如何使用Jsoup库开发Java爬虫,以实现...
Python爬虫遇到重定向URL问题时如何解决?
什么是重定向重定向是指当用户请求一个URL时,服务器返回一个中断请求的URL的响应。这种情况通常发生在网站对URL进行了修改或者重定向到其他页面的情况下。其中,如果处理不当开发,可能会导致爬虫无法获取所需的数据,从而影响爬虫的效果。出现重定向的原因 网站更新:当网站对URL进行了修改或者重定向到其他页面时,爬虫程序访问的原始URL可能会被重定向到新的URL。 防止爬虫:有些网站为了防止被...

Python爬虫:url中带字典列表参数的编码转换
平时见到的url参数都是key-value, 一般vlaue都是字符串类型的如果有幸和我一样遇到字典,列表等参数,那么就幸运了python2代码import json from urllib import urlencode # 1. 直接将url编码 params = { "name": "Tom", "hobby": ["ball", "swimming"], "bo...
Python爬虫:利用百度短网址缩短url
写爬虫程序的时候,会遇到目标网址太长,存入数据库存入不了的情况,这时,我们可以通过百度短网址服务将网址缩短之后再存入百度短网址:http://dwz.cn/百度短网址接口文档:http://dwz.cn/#/apidoc以下是python代码# -*- coding: utf-8 -*- # @File : baidu_short_url.py # @Date : 2018-08-2...
Python爬虫:urlencode带参url的拼接
如果连接直接这样写,看上去很直观,不过参数替换不是很方便,而且看着不舒服https://www.mysite.com/?sortField=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&pageIndex=3&pageSize=20可以使用如下方式美化代码from urllib import urlencode url = "https://www.m....
Python爬虫:利用urlparse获取“干净”的url
urlparse 类似处理操作系统路径的 os.path 模块,能够很好的处理网址路径导入模块python3from urllib.parse import urlparse, urljoinpython2from urlparse import urlparse, urljoin使用测试url = "https://cdn.itjuzi.com/images/51202bf56a442ba93....
python爬虫URL编码和GETPOST请求 | python爬虫实战之三
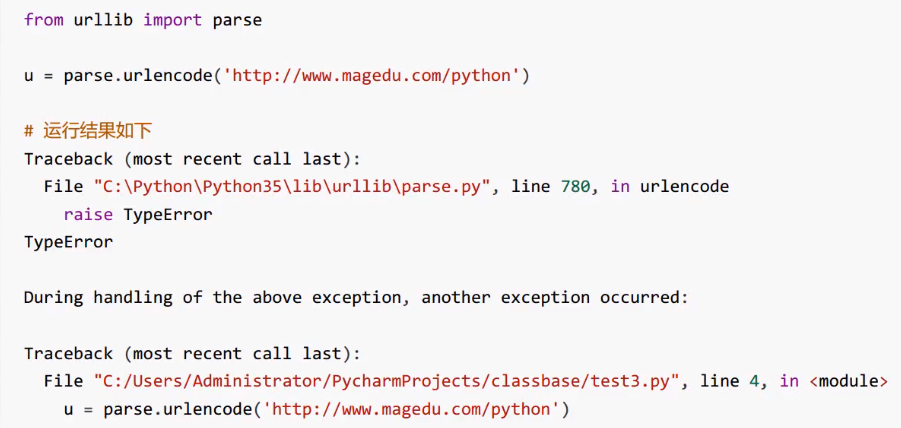
urllib.parse模块 该模块可以完成对url的编解码。先看一段代码,进行编码。 此时查看结果,程序显示TypeError错误,urlencode函数第一参数要求是一个字典或者二元组序列。我们修改代码: from urllib import parse d = { 'id':1 'name': 'tom' } url = 'http://www.magedu....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
飞天洛神云网络
阿里云飞天洛神云网络
+关注