
K-Means、层次聚类算法讲解及对iris数据集聚类实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~聚类(Clustering) 一个重要的非监督学习方法聚类-即是将相似的对象组成多个类簇,以此来发现数据之间的关系聚类(簇):数据对象的集合 在同一个聚类(簇)中的对象彼此相似 不同簇中的对象则相异聚类是一种无指导的学习:没有预定义的类编号聚类分析的数据挖掘功能 作为一个独立的工具来获得数据分布的情况作为其他算法(如:特征和分类)的预处理步骤聚类的“好....

【python机器学习】K-Means算法详解及给坐标点聚类实战(附源码和数据集 超详细)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~人们在面对大量未知事物时,往往会采取分而治之的策略,即先将事物按照相似性分成多个组,然后按组对事物进行处理。机器学习里的聚类就是用来完成对事物进行分组的任务一、样本处理聚类算法是对样本集按相似性进行分簇,因此,聚类算法能够运行的前提是要有样本集以及能对样本之间的相似性进行比较的方法。样本的相似性差异也称为样本距离,相似性比较称为距离度量。设样本....
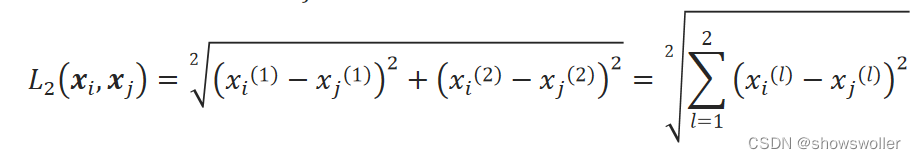
python 实现k-means聚类算法 银行客户分组画像实战(超详细,附源码)
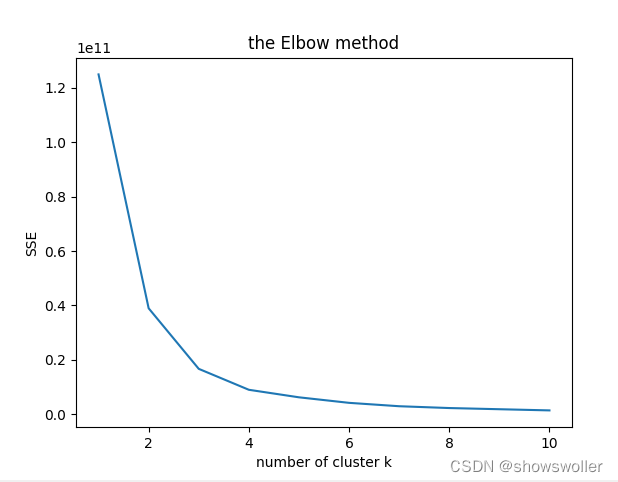
k-means具体是什么这里就不再赘述,详情可以参见我这篇博客k-means问题描述:银行对客户信息进行采集,获得了200位客户的数据,客户特征包括以下四个1:社保号码 2:姓名 3:年龄 4:存款数量 使用k-means算法对客户进行分组,生成各类型客户的特点画像数据集请点赞关注收藏后私信博主要肘部折线图如下 tips:利用肘部方法可以找到最佳的簇数,即看那个点之后逐渐....
使用Python实现K-means 算法-------文章中有源码
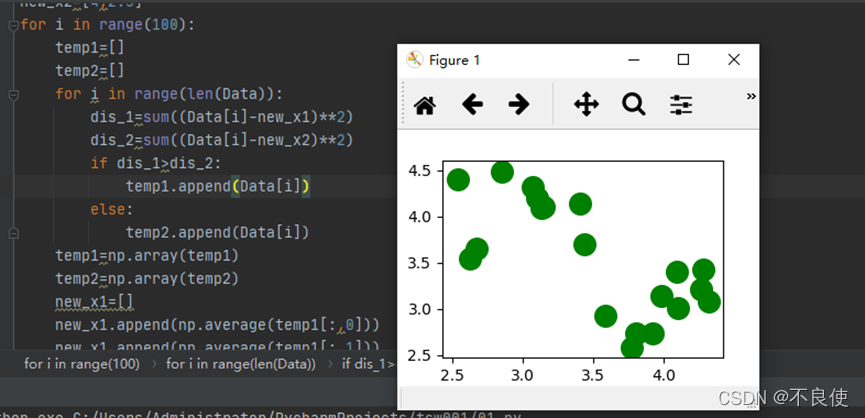
一、实验目的使用Python实现K-means 算法。二、实验原理(1)(随机)选择K个聚类的初始中心;(2)对任意一个样本点,求其到K个聚类中心的距离,将样本点归类到距离最小的中心的聚类,如此迭代n次;(3)每次迭代过程中,利用均值等方法更新各个聚类的中心点(质心);(4)对K个聚类中心,利用2,3步迭代更新后,如果位置点变化很小(可以设置阈值),则认为达到稳定状态,迭代结束。三、Python....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法更多源码相关

智能引擎技术
AI Online Serving,阿里巴巴集团搜推广算法与工程技术的大本营,大数据深度学习时代的创新主场。
+关注