
EMR集群JindoData的升级流程
对于已创建的EMR-3.40.0及以上版本或EMR-5.6.0及以上版本的集群,如果遇到JindoData已知问题或需要使用新功能,可按照本文进行JindoData的升级操作。
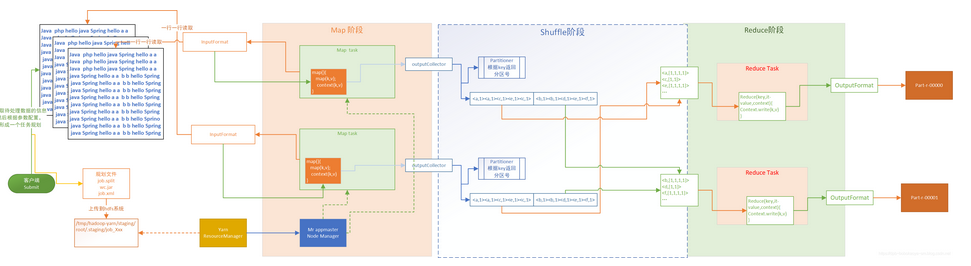
Hadoop之MapReduce03【wc案例流程分析】
上篇文件介绍了自定义wordcount案例的实现,本文来介绍下具体的执行流程流程图流程说明1.当客户端提交submit的时候客户端程序会根据我们输入的/wordcount/input地址找到需要统计的数据,根据我们的配置信息得到任务规划文件2.将任务规划文件上传到hdfs指定的位置。hadoop fs -ls /tmp/hadoop-yarn/staging/root/.stagin....
MapReduce V1:Job提交流程之JobClient端分析
我们基于Hadoop 1.2.1源码分析MapReduce V1的处理流程。MapReduce V1实现中,主要存在3个主要的分布式进程(角色):JobClient、JobTracker和TaskTracker,我们主要是以这三个角色的实际处理活动为主线,并结合源码,分析实际处理流程。下图是《Hadoop权威指南》一书给出的MapReduce V1处理Job的抽象流程图: 如上图,我们展开阴影.....

MapReduce V1:JobTracker处理Heartbeat流程分析
我们基于Hadoop 1.2.1源码分析MapReduce V1的处理流程。这篇文章的内容,更多地主要是描述处理/交互流程性的东西,大部分流程图都是经过我梳理后画出来的(开始我打算使用序列图来描述流程,但是发现很多流程在单个对象内部都已经非常复杂,想要通过序列图表达有点担心描述不清,所以选择最基本的程序流程图),可能看起来比较枯燥,重点还是关注主要的处理流程要点,特别的地方我会刻意标示出来,便于....
MapReduce V1:TaskTracker端启动Task流程分析
我们基于Hadoop 1.2.1源码分析MapReduce V1的处理流程。 TaskTracker周期性地向JobTracker发送心跳报告,在RPC调用返回结果后,解析结果得到JobTracker下发的运行Task的指令,即LaunchTaskAction,就会在TaskTracker节点上准备运行这个Task。Task的运行是在一个与TaskTracker进程隔离的JVM实例中执行,该JV....
MapReduce V1:MapTask执行流程分析
我们基于Hadoop 1.2.1源码分析MapReduce V1的处理流程。 在文章《MapReduce V1:TaskTracker设计要点概要分析》中我们已经了解了org.apache.hadoop.mapred.Child启动的基本流程,在Child VM启动的过程中会运行MapTask,实际是运行用户编写的MapReduce程序中的map方法中的处理逻辑,我们首先看一下,在Child类中....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce服务
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce hadoop
- mapreduce集群
- mapreduce spark
- mapreduce数据
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化